Intro
Fuzzy search algorithms (also known as similarity search algorithms) are a basis of spell-checkers and full-fledged search engines like Google or Yandex. For example, these algorithms are used to provide the "Did you mean ..." function.In this article I'll discuss the following concepts, methods and algorithms:
- Levenshtein distance
- Damerau-Levenshtein distance
- Bitap algorithm with modifications by Wu and Manber
- Spell-checker method
- N-gram method
- Signature hashing method
- BK-trees
So...
Fuzzy search is a very useful feature of any search engine. However, its effective implementation is much more complicated than implementing a simple search for an exact match.The problem of fuzzy string searching can be formulated as follows:
"Find in the text or dictionary of size n all the words that match the given word (or start with the given word), taking into account k possible differences (errors)."
For example, if you're requested for "machine" with two possible errors, find the words "marine", "lachine", "martine", and so on.
Fuzzy search algorithms are characterized by metric - a function of distance between two words, which provides a measure of their similarity. A strict mathematical definition of metric includes a requirement to meet triangle inequality (X - a set of words, p - metric):
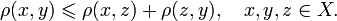
Meanwhile, in most cases a metric is understood as a more general concept that does not meet the condition above, this concept can also be called distance.
Among the most well-known metrics are Hamming, Levenshtein and Damerau-Levenshtein distances. Note that the Hamming distance is a metric only on a set of words of equal length, and that greatly limits the scope of its application.
However, in practice, the Hamming distance is useless, yielding more natural from the human point of view metrics, which will be discussed below.
Levenshtein distance
The Levenshtein distance, also known as "edit distance", is the most commonly used metric, the algorithms of its computation can be found at every turn.Nevertheless, it is necessary to make some comments about the most popular algorithm of calculation - Wagner-Fischer method.
The original version of this algorithm has time complexity of O(mn) and consume O(mn) memory, where m and n are the lengths of the compared strings. The whole process can be represented by the following matrix:
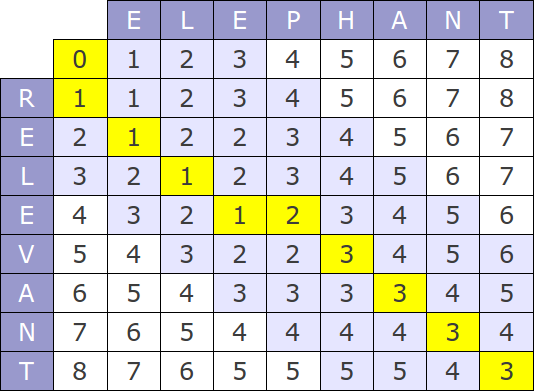
If you look at the algorithm's work process, it is easy to see that at each step only the last two rows of the matrix are used, hence, memory consumption can be reduced to O(min(m, n)).
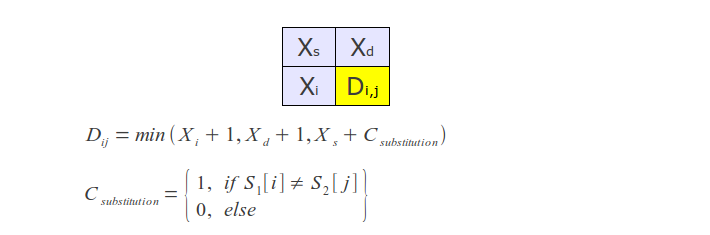
But that's not all - the algorithm can be optimized further, if no more than k differences should be found. In this case it is necessary to calculate only the diagonal band of width 2k+1 in matrix (Ukkonen cut-off), which reduces the time complexity to O (k min (m, n)).
Prefix distance
Usually it is necessary to calculate the distance between the prefix pattern and a string - ie, to find the distance between the specified prefix and nearest string prefix. In this case, you must take the smallest of the distances from the prefix pattern to all the prefixes of the string. Obviously, the prefix length can not be considered as a metric in the strict mathematical sense, what limits its application.Often, the specific value of a distance is not as important as fact that it exceeds a certain value.
Damerau-Levenshtein distance
This variation contributes to the definition of the Levenshtein distance one more rule - transposition of two adjacent letters are also counted as one operation, along with insertions, deletions, and substitutions.A couple of years ago, Frederick Damerau would ensure that most typing errors - transpositions. Therefore, this metric gives the best results in practice.

To calculate this distance, it suffices to slightly modify the regular Levenshtein algorithm as follows: hold not two, but the last three rows, and add an appropriate additional condition - in the case of transposition take into account its cost.
In addition to the above, there are many others sometimes used in practice distances, such as Jaro–Winkler metric, many of which are available in SimMetrics and SecondString libraries.
Fuzzy search algorithms without indexing (Online)
These algorithms are designed to search against previously unknown text, and can be used, for example, in a text editor, document viewers or web browsers to search the page. They do not require text pre-processing and can operate with a continuous stream of data.Linear search
A simple one-by-one metric computation (eg, Levenshtein metric) for words of the input text. When you use metric limitation, this method allows to achieve optimum speed.But at the same time, than more k, than more time grows. Asymptotic time complexity - O (kn).
Bitap (also known as Shift-Or or Baeza-Yates-Gonnet, and it's modifications by Wu and Manber)
Bitap algorithm and its various modifications are most often used for fuzzy search without indexing. Its variation is used, for example, in unix-utility agrep, which one functions like the standard grep, but it supports errors in the search query, and even provides a limited ability to use regular expressions.For the first time the idea of this algorithm is proposed by Ricardo Baeza-Yates and Gaston Gonnet, the relevant article published in 1992.
The original version of the algorithm deals only with letter substitutions, and, in fact, computes the Hamming distance. But later Sun Wu and Udi Manber suggested a modification of this algorithm for computing the Levenshtein distance, ie brought support insertions and deletions, and developed the first version of agrep utility.
Bitshift operation

Insertions
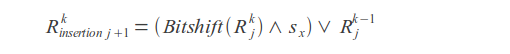
Deletions
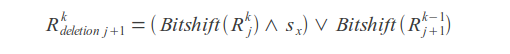
Substitutions
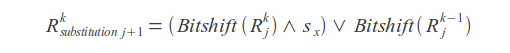
Result value

Where k - error count, j - letter index, sx - letter mask (in mask one bits are placed at positions corresponding to the positions of this letter in the query).
Query match or mismatch is determined by the last bit of the result vector R.
High speed of this algorithm is ensured by the bit parallelism - calculations can be performed on 32 or more bits in a single operation.
In this case, a trivial implementation supports the search for the words shorten than 32 symbols. This restriction is caused by the width of a standard type int (32-bit architectures). We can use wider types, but it's usage may slow down the algorithm's work.
Despite the fact that the asymptotic time of this algorithm O (kn) equals linear method's time, it is much faster when the query is long and number of errors k more than 2.
Testing
Testing was performed on the text of 3.2 million words, average word length - 10.Exact search
Search time: 3562 msLinear search using Levenshtein metric
Search time with k = 2: 5728 msSearch time with k = 5: 8385 ms
Bitap with Wu-Manber modifications search
Search time with k = 2: 5499 msSearch time with k = 5: 5928 ms
It is obvious that a simple iteration using the metric, in contrast to the Bitap algorithm, highly depends on the number of errors k.
At the same time, if we should search in constant large text, the search time can be greatly reduced by making text preprocessing (indexing).
Fuzzy search algorithms with indexing (Offline)
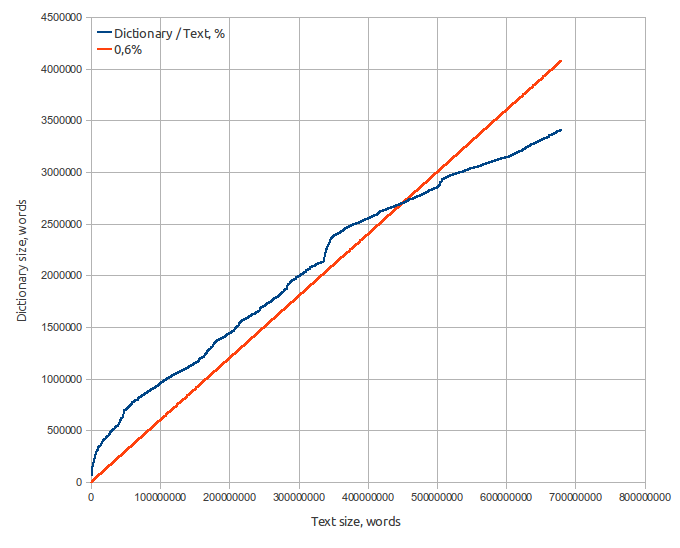
Feature of all fuzzy search algorithms with indexing is that the index is based on the dictionary compiled by the original text or list of records in a database.These algorithms use different approaches to solve problem - some of them use reduction to exact search, while others use properties of metrics to construct various spatial structures and so on.
At the first step, we construct a dictionary using the original text, which would contain words and their position in text. Also, it is possible to calculate the frequency of words and phrases to improve search results.
It is assumed that the index, as well as dictionary, entirely loaded into memory.
Dictionary specifications:
- Source text — 8.2 Gb Moshkow's library (lib.ru), 680 millions of words;
- Dictionary size — 65 Mb;
- Word count - 3.2 million;
- Average word length — 9.5 letters;
- Average word square length — 10.0 letters;
- Russian alphabet (32 letters). Words that contain characters not in the alphabet, are not included in the dictionary.
Spell-checker method
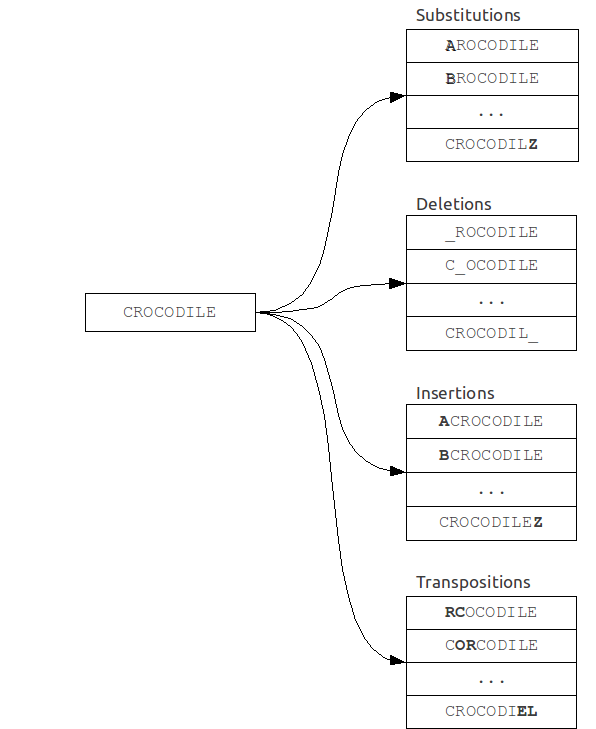
As the name implies, this algorithm is often used in spelling correction systems (ie, spell-checker systems), when the size of the dictionary is small, or else when speed is not the main criterion.It is based on reducing the problem of fuzzy search to the problem of exact search.
A set of "mistaken" words is built from original query. Then every word from this set is searched in the dictionary for exact match.
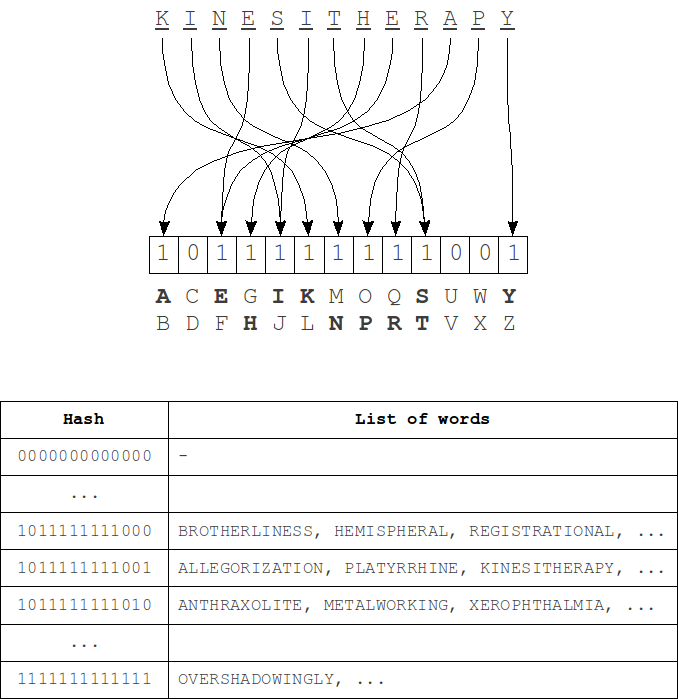
Its time complexity is strongly dependent on the number of errors k and the alphabet size |A|, and for a binary search over the dictionary is:
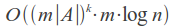
For example, in case of error count k = 1 and word length of 7 in the English alphabet set of misspelled words will have about 370 words, so we need to make 370 queries in the dictionary, which is quite acceptable.
But even at k = 2 the size of this set will be more than 75,000 words, which corresponds to a complete iteration over a small dictionary and, therefore, time is sufficiently large. In this case, we should not forget also that for each of such words are necessary to search for an exact match in the dictionary.
Specialties:
The algorithm can be easily modified to generate "mistaken" words using arbitrary rules and, moreover, does not require any dictionary preprocessing or additional memory.Possible improvements:
We can generate not a whole set of "mistaken" words, but only those that are most likely to occur in real situations, like words with common spelling mistakes or typos.N-gram method
This method was invented long ago, and is the most widely used because its implementation is relatively simple and it provides a reasonably good performance. This algorithm is based on the principle:"If the word A matches with the word B considering several errors, then they will most likely have at least one common substring of length N".
These substrings of length N are named "N-grams".
At indexing step, the word is partitioned into N-grams, and then the word is added to lists that correspond each of these N-grams. At search step, the query is also partitioned into N-grams, and for each of them corresponding lists are scanned using the metric.
The most frequently used in practice are trigrams - substrings of length 3. Choosing a larger value of N leads to a limitation on the minimum length of words at which error detection is still possible.
Specialties:
N-gram algorithm doesn't find all possible spelling errors. Take, for instance, the word VOTKA (which must be corrected to VODKA, of course), and divide it into trigrams: VOTKA > VOT OTK TKA - we can see that all of these trigrams contain an error T. Thus, the word "VODKA" will not be found because it does not contain any of the trigrams, and will not get into their lists. The shorter the word and more errors in it, the higher chance that it won't contains in corresponding to query N-grams lists and will not appear in the result set.Meanwhile, N-gram method leaves ample scope for using custom metrics with arbitrary properties and complexity, but there remains a need for brute force of about 15% of the dictionary.
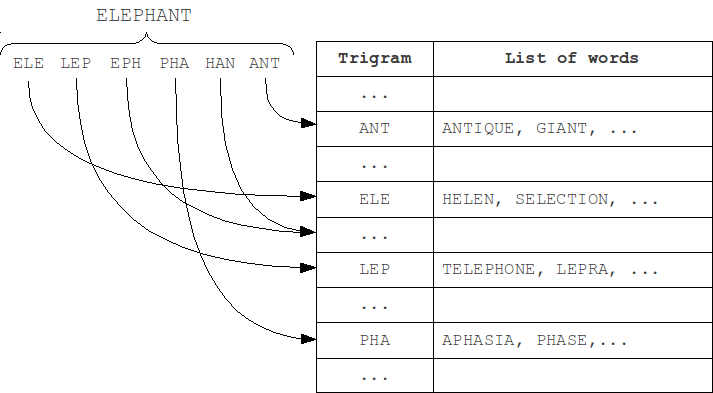
We can separate N-gram hash tables by position of N-gram in the word (first modification M1). As the length of a word and the query can't differ by more than k, and the position of N-grams in the word can't differ by more than k. Thus, we should check only table that corresponds to the N-gram position in the word, and k tables to the left and to the right, total 2k+1 neighboring tables.
We can even slightly reduce the size of iterating set by separating tables by word length, and, similarly, scanning only the neighboring 2k+1 tables (second modification M2).
Signature hashing
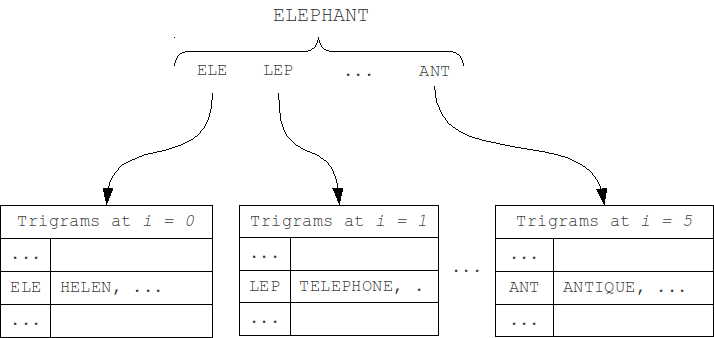
This algorithm is described in L. M. Boytsov's article "Signature hashing". It is based on a fairly obvious representation of the "structure" of the word as a bit word, used as a hash (signature) in the hash table.When indexing, such hashes are calculated for each word and this word is added in the corresponding table row. Then, during the search the hash is computed for a query and set of adjacent hashes that differ from the query's hash with no more than k bits is generated. For each of these hashes we iterate over corresponding list of words using the metric.
The hash computing process - for each bit of the hash a group of characters from the alphabet is matched. Bit 1 at position i in the hash means that there is a symbol of i-th group of the alphabet in the word. Order of the letters in the word is absolutely does not matter.
Single character deletion either does not change the hash value (if the word still have characters from the same group of the alphabet), or bit of corresponding group will be changed to 0. When you insert a similar manner or a bit of get up at 1 or no changes will be. Single character substitution a bit more complicated - the hash can either remain unchanged or will change in 1 or 2 bits. In case of transpositions there are no changes in the hash because the order of symbols at the hash construction does not matter as noted earlier. Thus, to fully cover the k errors we need to change at least 2k bits in the hash.

Average time complexity with k "incomplete" (insertions, deletions and transpositions, as well as a part of substitutions) errors:
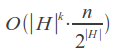
Specialties:
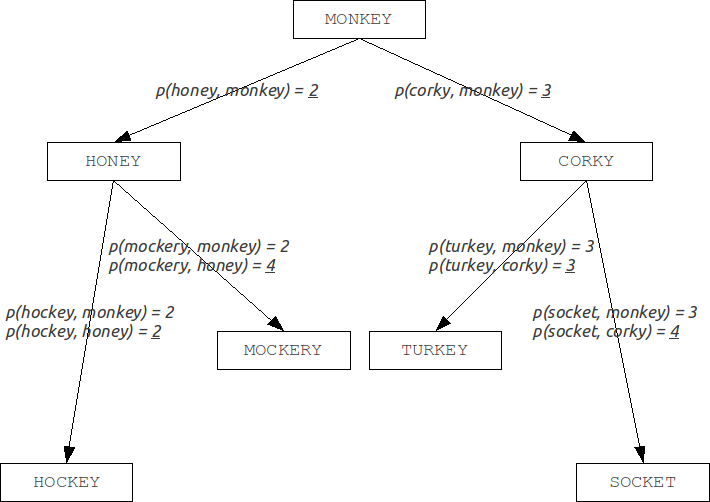
The fact that the replacement of one character can change two bits at a time, the algorithm that works with, for example, changing of 2 bits in hash, in reality won't return the full set of results because of lack of significant (depending on the ratio of the hash size to the alphabet size) amount of the words with two substitutions (and the wider the hash, the more frequently two bits will be changed at the same and the more incomplete set will be returned). In addition, this algorithm does not allow for prefix search.BK-trees
Burkhard-Keller trees are metric trees, algorithms for constructing such trees based on the ability of the metrics to meet the triangle inequality:This property allows metrics to form the metric spaces of arbitrary dimension. These metric spaces are not necessarily Euclidean, for example, the Levenshtein and Damerau-Levenshtein metrics form a non-Euclidean space. Based on these properties, we can construct a data structure for searching in a metric space, which is Barkhard-Keller tree.
Improvements:
We can use the ability of some metrics to calculate the limited distance, setting an upper limit to the sum of the maximum distance to the node descendants and the resulting distance, which will speed up the process a bit: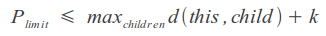
Testing
Testing was performed on a laptop with Intel Core Duo T2500 (2GHz/667MHz FSB/2MB), 2Gb RAM, OS — Ubuntu 10.10 Desktop i686, JRE — OpenJDK 6 Update 20.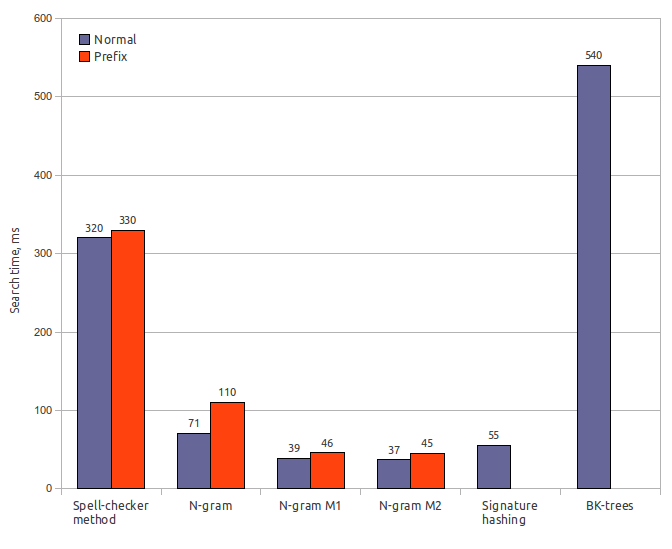
Testing was performed using Damerau-Levenshtein distance with error count k = 2. Index size is specified including dictionary size (65 Mb).
Spell-checker method
Index size: 65 MbSearch time: 320 ms / 330 ms
Result recall: 100%
N-gram (original)
Index size: 170 MbIndex creation time: 32 s
Search time: 71 ms / 110 ms
Result recall: 65%
N-gram (first modification)
Index size: 170 MbIndex creation time: 32 s
Search time: 39 ms / 46 ms
Result recall: 63%
N-gram (second modification)
Index size: 170 MbIndex creation time: 32 s
Search time: 37 ms / 45 ms
Result recall: 62%
Signature hashing
Index size: 85 MbIndex creation time: 0.6 s
Search time: 55 ms
Result recall: 56.5%
BK-trees
Index size: 150 MbIndex creation time: 120 s
Search time: 540 ms
Result recall: 63%
Conclusion
Most of fuzzy search algorithms with indexing are not truly sublinear (i.e., having an asymptotic time of O (log n) or below), and their performance usually depends on N. Nevertheless, multiple enhancements and improvements make it possible to achieve sufficiently small operational time, even with very large dictionaries.There is also another set of various and inefficient methods, based on adaptations of techniques and methods from other subject areas to the current. Among these methods is the prefix tree (Trie) adaptation to fuzzy search problems, which I left neglected due to its low efficiency. But there are also algorithms based on the original approaches, for example, the Maass-Novak algorithm, it has sublinear asymptotic time, but it is highly inefficient because of the huge constants hidden behind asymptotic time estimation, which leads to a huge index.
The use of fuzzy search algorithms in real search engines is closely related to the phonetic algorithms, lexical stemming algorithms, which extract base part from different forms of the same word (for example, that functionality provided by Snowball), statistic-based ranking or the use of some complex sophisticated metrics.
This link http://code.google.com/p/fuzzy-search-tools takes you to my Java implementation of the following stuff:
- Levenshtein Distance (with cutoff and prefix version);
- Damerau-Levenshtein Distance (with cutoff and prefix version);
- Bitap (Shift-Or with Wu-Manber modifications);
- Spell-checker Method;
- N-Gram Method (with some modifications);
- Signature Hashing Method;
- Burkhard-Keller (BK) Trees.
It is worth noting that in the process of researching this subject I've made some own work, which allows to reduce the search time significantly due to a moderate increase in the index size and some restrictions on freedom of used metrics. But that's another cool story.
Links:
- Java source codes for this article. http://code.google.com/p/fuzzy-search-tools
- Levenshtein distance. http://en.wikipedia.org/wiki/Levenshtein_distance
- Damerau-Levenshtein distance. http://en.wikipedia.org/wiki/Damerau–Levenshtein_distance
- Shift-Or description with Wu-Manber modifications, in Deutsch. http://de.wikipedia.org/wiki/Baeza-Yates-Gonnet-Algorithmus
- N-gram method. http://www.cs.helsinki.fi/u/ukkonen/TCS92.pdf
- Signature hashing. http://www.springerlink.com/content/1aahunb7n41j32ne/
- Signature hashing in Russian. http://itman.narod.ru/articles/rtf/confart.zip
- Information retrieval and fuzzy string searching. http://itman.narod.ru/english/index.htm
- Shift-Or and some other algorithms implementation. http://johannburkard.de/software/stringsearch/
- Fast Text Searching with Agrep (Wu & Manber). http://www.at.php.net/utils/admin-tools/agrep/agrep.ps.1
- Damn Cool Algorithms - Levenshtein automata, BK-tree, and some others. http://blog.notdot.net/2007/4/Damn-Cool-Algorithms-Part-1-BK-Trees
- BK-tree Java implementation. http://code.google.com/p/java-bk-tree/
- Maass-Novak algorithm. http://yury.name/internet/09ia-seminar.ppt
- SimMetrics metric library. http://staffwww.dcs.shef.ac.uk/people/S.Chapman/simmetrics.html
- SecondString metric library. http://sourceforge.net/projects/secondstring/
This comment has been removed by the author.
ReplyDeleteHello everyone..Welcome to my free masterclass strategy where i teach experience and inexperience traders the secret behind a successful trade.And how to be profitable in trading I will also teach you how to make a profit of $12,000 USD weekly and how to get back all your lost funds feel free to email me on( brucedavid004@gmail.com ) or whataspp number is +22999290178
Delete
DeleteI also lost about $75,000 to an IQ option broker and 2 fake binary option website as well but I am sharing my experience here so as to enlighten and educate everyone that is losing money or has lost money to a scam including binary options, dating scams,Recover all your lost money to Bitcoin and other Crypto currency, mortgage/realestate scams and fake ICOs.However , I have been able to recover all the money I lost to the scammers with the help of a recovery professional and I am pleased to inform you that there is hope for everyone that has lost money to scam. Contact this via mail (lisakimberly@gmail.com ) or via whatsapp (+18133243782) she will help you recover your funds.
This comment has been removed by the author.
ReplyDeleteHrm, is there any reason you decided not to test suffix arrays/trees? It seems like they are one of the most popular approaches to fuzzy search.
ReplyDeleteAnother fairly new technique is called canopy clustering. It's beholden to the triangle inequality, but it's a great initial blocking method.
For n-gram-based techniques, you may want to check an open-source C++ package at http://flamingo.ics.uci.edu/
ReplyDeleteA trie-based solution has been shown to be very efficient, especially for instant search. Check http://ipubmed.ics.uci.edu/
Chen Li
Richard Minerich said:
ReplyDelete> Hrm, is there any reason you decided not to
> test suffix arrays/trees? It seems like they
> are one of the most popular approaches to fuzzy
> search.
But suffix arrays only find matches at the beginning of the sentence. If there is an error at char two then how will you get a good fuzzy match?
Richard Minerich said:
> Another fairly new technique is called canopy
> clustering. It's beholden to the triangle
> inequality, but it's a great initial blocking
> method.
I skimmed this paper and I fail to see the connection to fuzzy string matching.
Thank you ! A concise and effective explanation. It would be great if some use case scenarios are included.
ReplyDeleteRichard Minerich:
ReplyDeleteIn fact, I tried to use suffix array and I wrote the algorithm (and implemented it in Java) based on the following steps:
1. Split the word into k + 1 parts skipping one letter between them: "crocodile" (k = 2) => "cro_cod_le"
2. Search for each part in suffix array "cro" => "crocodile"[13421], "macro"[412345] (word index in the dictionary shown in square brackets)
3. Intersect found word indexes to obtain the result (and filter them using levenshtein to remove rare mismatches)
It works really fast but requires a lot of space (about 1G for 3.2M words)
The problem is that we need to store inverse mapping from word dictionary index to it's suffix array index.
If you want to see this implementation, I can place it somewhere.
I'll try to read about "canopy clustering" soon.
Very interesting and detailed exposition of current techniques!
ReplyDeleteAny reason why you left out soundex? (I know it is very language specific, but it's really effective and can result in really good performance when the process of finding a soundex match is converted to one of an exact prefix match using Suffix Arrays, as Richard Minerich mentioned).
I've done some work on this here: http://dhruvbird.com/autocomplete.pdf
Your previous post is on soundex, so it seems like a natural incorporation of that technique to the one of inexact string match (albeit not a general one). But, in practice, I would think many use cases would ask for inexact phonetic string matching.
ReplyDeleteChen Li:
ReplyDeleteThe FLAMINGO project looks very interesting.
Also I've implemented a lot of fuzzy search things for The Xapian Project (it is in C++ too) - some search algorithms, phonetic matching, context-sensitive spelling correction (including splitted and sticked words), transliteration, language detection.
This comment has been removed by the author.
ReplyDeleteRichard,
ReplyDeleteSuffix trees can be used for approximate string searching in a way similar to n-gram matching. This approach is called pattern partitioning.
I have never used suffix trees or arrays to this end, because of the following:
1) Uncompressed suffix trees/arrays are not compact.
2) There are sophisticated compact versions (check the works of Navarro, Mäkinen, and Ferragina), but there is certainly a tradeoff in speed/index size involved. Not sure if those can beat an optimized n-gram index. I would love, however, to see these methods tested :-)
3) I overall do not like pattern partitioning methods, because the average search time grows linearly with the dictionary size. In many case, this *CAN* be important.
Suffix trees/arrays are more pertinent in molecular biology, but for a dictionary searching, they seem to be be an overkill. Here, you can do a much better job with some of the super-linear-index methods, or you can use a pair of regular tries (a second is over reversed strings) to get an excellent performance.
BTW, I recently tested Chen Li's Flamingo n-gram implementation. It is very efficient (in fact 1.5-2 times faster than my own n-gram-based code) and it also supports prunning, in case you don't care for 100% recall
The advantage of a suffix tree or trie approach is that you don't have to calculate string distance for your entire dictionary, since this can become expensive.
ReplyDeleteAs for growing linearly with dictionary size, while true, this is easily defeated through sharding which scales in similar fashion.
Chris, no doubt about a trie-like structure, I doubt that ST is the right trie-like structure. Unless u need to search for arbitrary substrings.
ReplyDeleteAwhile back I ran across http://norvig.com/spell-correct.html, which covers writing a spell checker in python. It's an interesting read if anyone is interested.
ReplyDeleteItman, good call. I have the bad habit of conflating suffix-trees and tries. Indeed, I did mean tries.
ReplyDeleteThis comment has been removed by the author.
ReplyDeleteJoseph Turian: Suffix based approach can actually find any common substring down to a length you specify.
ReplyDeleteCanopy Cluster is more of a pre-processing step to speed things up. You cluster your target corpus first and so can avoid the O(N^2) problem later on by only comparing within one cluster.
ReplyDeleteI myself haven't had much luck with straight n-gram technqiues, it's just too slow. My primary corpus is a few million names though, so I can see how I would need different sets of techniques than someone say, indexing academic papers.
Nikita Smetanin:
That is a big downside downside of the suffix based approaches for sure. It's all about the time-space tradeoff.
Itman:
I'll look into Pattern Partitioning. Thanks for the tip!
you should have a look at the Levenshtein Automata
ReplyDeletehttp://blog.notdot.net/2010/07/Damn-Cool-Algorithms-Levenshtein-Automata
its the best solution i have found so far
This comment has been removed by the author.
ReplyDeleteDo you happen to have the dictionnary used for your tests available somewhere ?
ReplyDeleteI've implemented a solution for this exact problem using tries. And since you discarded it because you say it's not efficient enough, I'd like to compare it to your results :)
Thanks
This dictionary is always available here.
ReplyDeleteI've written a blog article about fuzzy search with a Trie.
ReplyDeletehttp://blog.vjeux.com/2011/c/c-fuzzy-search-with-trie.html
As for performances, I search every word at a distance 2 of the 400 most popular english words. The dictionnary contains 3 millions words. It takes 22 seconds on my old 2Ghz server to run it. It takes an average of 55ms per fuzzy search and generates an average of 247 results.
The inputs and times look similar to the ones you obtain in your benchmarks. When I will have some time, I will update my code in order to take your inputs, this way you'll be able to compare on your test computer.
Hi everybody,
ReplyDeleteNever mind my previous comment on Nick's blog. I missed a point and, apparently, Nick's solution makes sense.
Hi, for developers who are interested in a new algorithm that combines token based, character based, and phonetic based algorithms into one fast and accurate name matching technology visit http://www.fame-api.com
ReplyDeleteMany thanks Nikita, this was exactly the concise and practical overview I was looking for.
ReplyDeleteVery nice! I've to deal with the search engine in company's web-based product and we're using htdig for this. Your article was very helpful in understanding fuzzyalgos, I'll implement these in our product :)
ReplyDeleteGood day!
ReplyDeleteI was wondering if you could help me in my report. It is about the use of "FUZZY LOGIC" in searching the database. I've searched the net for the basic concepts of fuzzy logic and I always get these three steps: fuzzification, inference engine and
defuzzification.
Now, my problem is this: how exactly can I apply these three steps with the algorithms that you've discussed here? I think they will fit the fuzzification stage but how about the other two?
Thanks in advance..!
Sorry, but this article is about fuzzy search, which has nothing in common with fuzzy logic. I hope you'll find answers somewhere else.
DeleteAh, OK... Thanks anyway..!
DeleteLiked your post very much... I have been considering a consume-order-agnostic approach to approximate match, as an extension to exact match (presented here: http://arxiv.org/pdf/1209.4554v1.pdf). I think there might be an advantage here - would you agree?
ReplyDeleteI like this post. However I would disagree that the Trie based methods are slow. Here is example of Fuzzy search based on Trie, it works pretty fast:
ReplyDeletehttp://www.softcorporation.com/products/people/index.html
You're right, I've investigated the Levenshtein automata algorithm (which works on DAWG - a general case of a trie) and it seems to be fast enough with a moderate index (DAWG) size.
DeleteFor large string and larger errors, though, different methods are required. Because trie has a cost O(length^k alphabet_size^k). This works for names because, both length and k are small.
DeleteI downloaded the dictionary, put it in our MatchMaker tool, and ran queries against it in around 10 ms. Index-size is around 110 MB and it calculates the full Damerau-Levenshtein distance with unbounded error-correction.
ReplyDeleteThe same index can even do a block-edit calculation (blocks of strings are shifted for cost 1!) within 20 ms.
Optionally you can couple an approximate phonetics to it or do all kinds of extra comparison.
So THERE IS A LEVENSHTEIN INDEX type.
Yes, I know about Levenshtein automata, I implemented and tested it some time ago, but unfortunately I'd no enough time to write an article about it and some other very fast algorithms. Maybe I'll publish my Levenshtein automata java source code if it still exists.
DeleteHowever, I think that Levenshtein automata may have performance issues if you store them in external memory (because of its structure), so this case should be analyzed separately.
I did further tests with another Damerau-Levenshtein index type based on automata. It doesn't preprossess any potential error, but does realtime computation of all edit choices:
ReplyDeleteup to 1 error: below 1 ms
up to 2 errors:around 5 ms
up to 3 errors:around 15 ms
If you don't believe it, I can give more info!
One can do better than 1 ms easily.
ReplyDeleteAnybody know or can guess what algorithm QSR NVivo 10 use to find the exact or fuzzy text matching? The software works like this: store certain documents containing whatever text and in any language; then you can start searching for a certain word or multiple words. It does effectively catch the related words with its synonyms and it builds Word Tree Map for it. How does it do that? I mean what type of word distance calculations do they use? do they have a dictionary or do they use Wordnet or what?
ReplyDeleteThank you for sharing valuable information. Nice post. I enjoyed reading this post. The whole blog is very nice found some good stuff and good information here Thanks..Also visit my page Design and multimedia At 21st and century experience counts a lot as we believe that the single most important elements in mastering any task is experience.
ReplyDeleteAM Field Engineer from Japan, I am not used to this but i have to do this because i want the world and entire earth to know about Lord Zilialia. He is a blessing to man kind and a blessing to me in particular. Search no more for help any where your help is come. Just contact Lord Zilialia on spellcaster1202@gmail.com and you will be glad you did. Even Japanese do need help.
ReplyDeleteLearning to spell helps to cement the connection between the letters and their sounds, and learning high-frequency "sight words" to mastery level improves both reading and writing. English writing system is not merely to ensure accurate pronunciation of the written word – it is to convey meaning. https://vocabmonk.com helps you to learn new words with their spellings, meaning and pronunciation.
ReplyDeleteTry it..!!
Nice blog, very good information about Search algorithms, software development and so on. Aparajayah Technology in Madurai offers Web Development Service.
ReplyDeleteNot sure if my earlier comment got through. Writing again.
ReplyDeleteHey there. I'm currently working on some String Matching Algorithms and came across your blog. I'm not sure if you have any experience in Name matching using Fuzzy Logic - it's a bit of a challenge to include Language & Cultural heuristics in the Levenshtein criteria or any others.
I'm currently working on sorting out Names and mapping them with fuzzy logic - end result is a Contact Management App. Let me know if you're interested to check this out, and I'd really appreciate some help if you've already done some work here. Reach out to me on my email - arun.ravijigmail.com
Great Blog btw.
what is difference between Levenshtein distance and
ReplyDeleteDamerau-Levenshtein distance
download lagu mp3 terbaru gratis
ReplyDeleteAPKPLAY.MOBI
ReplyDeleteDownload Lagu
Streaming Movie Free
Httpmuviza.com
Nice Post
ReplyDeleteDownload Video Youtube
Stafaband Mp3
Stafaband
do you know where to download youtube videos to various formats, without ads and free ini ada web download video youtube dengan berbagai format and allows you to retrieve files youtube videos and save to your computer mp3 format, video mp4, 3gp go to tempatvideo.com
ReplyDeleteThis comment has been removed by a blog administrator.
ReplyDeleteMuveHits
ReplyDeleteLAGU MP3
APLIKASI APK
DOWNLOAD Video
Lirik Lagu
Unduh Lagu
Nice share
ReplyDeleteApkLagi
News Apps Android
Top Download Apps Android
Hits Download Apps
Thank you for wonderful post ! More power to you !
ReplyDeletenice info,,,
ReplyDeletestafaband-lagu
mp3mantapnet
mp3mantap
cakra69
freshlaguterbaru
stafabandsharelagu
namelagu
likelagu
suhump3-download lagu terbaru
Excellent post, I wait for his next post
ReplyDeletePlease click to play,if you wanna join casino online. Thank you
goldenslot
gclub online
gclub casino
Gclub
Pinoy Tambayan | Pinoy Tv | Pinoy Lambingan | Pinoy Tv Shows | Pinoy Ako Online Tambayan | Pinoy Teleserye | Pinoy channel
ReplyDeletedengar-lagu
ReplyDeleteplaylagu
daftarlagu
lagugaul stafaband
pilihlagu stafaband
prolagu stafaband
situsmusik
ci3ntalagu
Thanks for your personal marvelous posting!
ReplyDeleteI quite enjoyed reading it, you happen to be a great author.
I will make sure to bookmark your blog and will often come back in the future.
I want to encourage that you continue your great posts, have a nice weekend!
Hey,
ReplyDeleteGreat article and so informative. Some things appeared new for me so in any case it was interesting. I'd also like to mention another good tool, like title corrector. With its help you can have excellent and plagiarism free title. It performs capitalization of any existing style, so no problems appear.
สโบเบ็ต
ReplyDeleteamazing post!
ReplyDeletevisit: wapmek.com
Thank you.
ReplyDeletejoker gaming
Scr888
ace333
I really enjoy the blog.Much thanks again. Really Great. salesforce Online Course
ReplyDeleteI think it is very difficult. I have never studied a defendant. Now, I want my children to learn. And better math. I'm good. เรื่องแปลก
ReplyDeleteFuzzy Matching : Such an awesome and well described post by author. Its a huge resource. Thanks for sharing with us.
ReplyDeletedownload Lagu Alfamusik
ReplyDeleteKumpulan Situs Download Lagu Mp3
ReplyDeletesamudramusik
Tanggamusik
emp3.site
เกมส์ ไพ่ออนไลน์ ยอดนิยม เล่นง่าย ได้เงินไว ได้เงินจริง การเล่นไพ่บาคาร่าในอดีต จะมีการเล่นกันเฉพาะแต่ในสถานคาสิโนเท่านั้น ผู้ที่ชื่นชอบการเล่นไพ่บาคาร่า หากประสงค์จะเล่นก็ต้องเดินทางไปยังสถานคาสิโน ซึ่งไม่มีในประเทศไทย ต้องเดินทางไปเล่นกันในต่างประเทศ
ReplyDeleteปัจจุบันเทคโนโลยีสื่อสารที่ทันสมัย ช่วยทำให้คนสามารถเล่นบาคาร่าออนไลน์กันได้ผ่านเว็บไซต์ผู้ให้บริการหรือผ่านแอพริเคชั่นบนมือถือ อำนวยความสะดวกให้แก่ผู้ชื่นชอบการเล่นบาคาร่าไม่ใช่น้อยเลยทีเดียว รูปแบบของ บาคาร่าออนไลน์ ที่นิยมเล่นกันเป็นรูปแบบของการเล่นกันแบบสดๆ ถ่ายทอดผ่านเว็บไซต์ผู้บริการ และมีเครื่องมือที่ช่วยให้ผู้เล่นสามารถเลือกวางเดิมพันได้ทั้งฝั่งผู้เล่น Player หรือ ฝั่งเจ้ามือ Banker และสามารถเลือกที่จะวางเดิมพันเฉพาะตาใดไม่วางตาใดก็ได้ หรือจะวางทุกตาไปก็ได้ ผู้เล่นสามารถวางใจได้ ว่าจะไม่มีการเล่นตุกติกใดๆ การแพ้ชนะวัดผลกันแบบแฟร์ๆ ไม่มีใครได้เปรียบเสียเปรียบกัน หากชนะเดิมพันก็ได้เงินกันจริงๆ เล่นบาคาร่า นับว่าเป็นที่นิยมอย่างแพร่หลายในหมู่ผู้ที่ชื่นชอบการเล่นบาคาร่าออนไลน์อย่างมากในปัจจุบัน และมีผู้ให้บริการ สมัครบาคาร่าออนไลน์ เปิดให้บริการผ่านเว็บไซต์กันเป็นจำนวนมาก อย่างไรก็ตาม การเล่นบาคาร่าออนไลน์ ผู้ที่จะเล่นต้องทำการเปิดบัญชีและฝากเงินเป็นเครดิตไว้กับเว็บไซต์ผู้ให้บริการก่อนจึงจะสามารถนำเครดิตนั้นไปเป็นเงินเพื่อใช้สำหรับการเดิมพันได้
ดังนั้นจึงเป็นการวางเงินเป็นการล่วงหน้าให้กับเว็บไซต์ผู้ให้บริการ ซึ่งนับว่ามีความเสี่ยง ดังนั้นความน่าเชื่อถือของเว็บไซต์ผู้ให้บริการเป็นสิ่งสำคัญอย่างมากที่ผู้ประสงค์จะเล่นบาคาร่าออนไลน์ต้องนำมาพิจารณา ว่าสามารถวางใจได้ว่า วางเงินแล้วเงินจะไม่หายและเมื่อชนะเดิมพันจะสามารถถอนเงินที่ชนะเดิมพันได้ทั้งหมดโดยไม่มีเงื่อนไข
บาคาร่า
KamvretLaguMp3az
ReplyDeleteLagu76
Nice Bro
thanks for Providing a Great Info
ReplyDeleteanyone want to learn advance devops tools or devops online training visit:
DevOps Training
DevOps Online Training
DevOps Training institute in Hyderabad
This is good post for software developer they learned from your post i like your post. See my podt on my site visit my site
ReplyDeleteThank you for your information
ReplyDeleteSTEPSBOBET เว็บแทงบอลออนไลน์ คาสิโนออนไลน์ ที่ดีที่สุดอันดับ 1 สมัคร sbobet แทงบอลสเต็ป กีฬาออนไลน์ บาคาร่าออนไลน์ สล็อตออนไลน์ ครบวงจร ให้บริการเดิมพันออนไลน์ทุกประเภท มีความน่าเชื่อถือ
เว็บแทงบอลออนไลน์อันดับ 1
สมัคร sbobet
สมัคร Lsm99
สมัคร Sclub
สมัคร Ace333
สมัคร League88 ลีค88
สมัคร Gclub
สมัคร King99
เว็บแทงบอลออนไลน์ คาสิโนออนไลน์ อันดับ 1
Nice post. It is really interesting. Thanks for sharing the post!
ReplyDeleteCSUF Career
This is really impressive article, I am inspired with your blog, do post like this, I am waiting for your next post.
ReplyDeleteAWS Online Training
AWS Training in Hyderabad
Amazon Web Services Online Training
mix.com/cvlampungservicekingcameranfoundation.ning.com/profiles/blogs/best-indonesian-coursesmedium.com/@lampungservice.comlampung.wikidot.com/main:layout
ReplyDeletelampungservice.comtempatservicehpdibandarlampung.blogspot.com
microformats.org/wiki/vcard-implementations
lampungservice.com
ReplyDeleteserviceiphonebandarlampung.blogspot.com
youtubelampung.blogspot.com
bimbellampung.blogspot.com
bateraitanam.blogspot.com
This comment has been removed by the author.
ReplyDeletenice blog, very informative.
ReplyDeleteLIC Indian
Bisnis
ReplyDeleteindonesia
lampung
Lampung
Lampung
lampung
Elektronika
Bisnis
Loved the post… now I’m really hungry. ??
ReplyDeleteitunes free gift card
want to customize your character in Roblox but don't have enough Robux here is solution use Roblox gift card generator tool and grab your free Roblox gift card code.
ReplyDeleteI can see all of the research that went into this article. Lots of time was spent gathering data. discover activate
ReplyDeleteebay quickbooks integration
ReplyDeleteIn this course you'll learn everything you need to know to crush the poker tables.
ReplyDeletedownload idn poker
I will teach you how a tight-aggressive approach to the game that will get you tons of profits through a fundamental understanding of psychology, poker strategy and tactics.
osg777
Master Fundamental Poker Strategies necessary to crush the poker tables
game duit asli
Understand Poker Psychology that will allow you to outplay your opponents and attack their weaknesses
idn live
Master Pre-Flop Strategies that to learn which hands you should and can play profitably
sbobet
Learn the essential Poker Math all poker players MUST know
joker123 terbaru
Understand Post-Flop Basics that will allow you to win more pots
http://judiayam.me/s128/
ReplyDeletePurely informative post. I admire you for taking time and allocating this resourceful articles here. Keep up with this admirable job and continue updating.
ReplyDeleteEnglish practice App | English speaking app
Heya i’m for the first time here. I found this board and I find It really useful & it helped me out much. I hope to give something back and help others like you helped me.
ReplyDeletehttp://www.daftarlegendasepakbola.web.id
IDN Poker
ReplyDeleteThis is great information and all relevant to me. I know when I engage with my readers on my blog posts, not only does it encourage others to leave comments, but it makes my blog feel more like a community – exactly what I want!
ReplyDeleteData Science Training in Hyderabad
Hadoop Training in Hyderabad
Java Training in Hyderabad
Python online Training in Hyderabad
Tableau online Training in Hyderabad
Blockchain online Training in Hyderabad
informatica online Training in Hyderabad
devops online Training
Read my blog
ReplyDeleteWordpress expert for hire
globalemployees
globalemployees
Pretty article! I found some useful information in your blog, it was awesome to read, thanks for sharing this great content to my vision, keep sharing....mule esb training
ReplyDeleteGood day! I could have sworn I’ve visited this web site before but after looking at a few of the articles I realized it’s new to me. Anyhow, I’m definitely pleased I came across it and I’ll be bookmarking it and checking back frequently! motorola display repair bangalore I need to to thank you for this fantastic read!! I absolutely loved every bit of it. I have you book marked to look at new stuff you post… vivo charging port replacement Hi, I do believe this is a great website. I stumbledupon it ;) I'm going to return yet again since I bookmarked it. Money and freedom is the best way to change, may you be rich and continue to guide other people. lg service center Bangalore
ReplyDeleteThis is a very good tip particularly to those new to the blogosphere. Short but very precise info… Thank you for sharing this one. A must read article! huawei display repair bangalore I couldn’t resist commenting. Perfectly written! asus display replacement Saved as a favorite, I love your website! onsite mobile repair bangalore
ReplyDeleteThis is very helpful writing for blog writer and also after read you post i am learn more of blog writing thank you...
ReplyDeleteData Science Training in Hyderabad
Hadoop Training in Hyderabad
selenium Online Training in Hyderabad
Devops Training in Hyderabad
Informatica Online Training in Hyderabad
Tableau Online Training in Hyderabad
Thanks for posting such an useful info....
ReplyDeleteSalesforce Online Training
I rarely share my story with people, not only because it put me at the lowest point ever but because it made me a person of ridicule among family and friends. I put all I had into Binary Options ($690,000) after hearing great testimonies about this new investment
ReplyDeletestrategy. I was made to believe my investment would triple, it started good and I got returns (not up to what I had invested). Gathered more and involved a couple family members, but I didn't know I was setting myself up for the kill, in less than no time all we had put ($820,000) was gone. It almost seem I had set them up, they came at me strong and hard. After searching and looking for how to make those scums pay back, I got introduced to maryshea03@gmail.com to WhatsApp her +15623847738.who helped recover about 80% of my lost funds within a month.
ReplyDeleteThank you for sharing such a great information.Its really nice and informative.hope more posts from you. I also want to share some information recently i have gone through and i had find the one of the best mulesoft tutorial videos
merhabalar;
ReplyDeleteSohbet
istanbul sohbet
ankara sohbet
almanya sohbet
eskişehir sohbet
konya sohbet
kayseri sohbet
adana sohbet
kürtçe sohbet
Nice post. I learn something totally new and challenging on blogs I stumbleupon on a daily basis. It's always exciting to read articles from other writers and use something from their sites.
ReplyDeleteSelenium Courses in Marathahalli
selenium institutes in Marathahalli
selenium training in Bangalore
Selenium Courses in Bangalore
best selenium training institute in Bangalore
selenium training institute in Bangalore
Greetings! Very helpful advice within this post! It's the little changes that produce the most important changes. Thanks for sharing!
ReplyDeleteBest Advanced Java Training In Bangalore Marathahalli
Advanced Java Courses In Bangalore Marathahalli
Advanced Java Training in Bangalore Marathahalli
Advanced Java Training Center In Bangalore
Advanced Java Institute In Marathahalli
Excellent article! We will be linking to this great post on our site. Keep up the good writing.
ReplyDeleteSelenium Courses in Marathahalli
selenium institutes in Marathahalli
selenium training in Bangalore
Selenium Courses in Bangalore
best selenium training institute in Bangalore
selenium training institute in Bangalore
Poker online situs terbaik yang kini dapat dimainkan seperti Bandar Poker yang menyediakan beberapa situs lainnya seperti http://62.171.128.49/hondaqq/ , kemudian http://62.171.128.49/gesitqq/, http://62.171.128.49/gelangqq/, dan http://62.171.128.49/seniqq. yang paling akhir yaitu http://62.171.128.49/pokerwalet/. Jangan lupa mendaftar di panenqq silakan dicoba ya boss
ReplyDeletehadoop training in hyderabad iam enjoyed while reading your blog .thanks for shaing and keep sharing
ReplyDelete
ReplyDeleteI'm very happy to search out this information processing system. I would like to thank you for this fantastic read!!
GCP Online Training
Google Cloud Platform Training In Hyderabad
Google Cloud Platform Training
Google Cloud Platform Training Online
Why is it the number 1 online casino G Club to this day In this gclub era, we can't deny that In the social age, there is an influence in daily life. The internet system is already quite OK. We are therefore
ReplyDeleteMau Cari Situs Judi Online Aman dan Terpercaya? Banyak Bonusnya?
ReplyDeleteDi Sini Tempatnya.
DIVAQQ, Agen BandarQ, Domino99, Poker Online Terpercaya DI INDONESIA
100% MUDAH MENANG di Agen DIVAQQ
Daftar > Depo > Main > Menang BANYAK!
Deposit minimal Rp. 5.000,-
Anda Bisa Menjadi JUTAWAN? Kenapa Tidak?
Hanya Dengan 1 ID bisa bermain 9 Jenis Permainan
* BandarQ
* Bandar 66
* Bandar Poker
* Sakong Online
* Domino QQ
* Adu Q
* Poker
* Capsa Susun
* PERANG BACCARAT (NEW)
BONUS SETIAP MINGGU NYA
Bonus Turnover 0,5%
Bonus Refferal 20%
MARI GABUNG BERSAMA KAMI DAN MENANGKAN JUTAAN RUPIAH!
Website : DIVAQQ
WA : +85569279910
DIVAQQ AGEN JUDI DOMINO QQ ONLINE TERPERCAYA DI INDONESIA MENERIMA DEPOSIT VIA PULSA 24 JAM
DIVAQQ | AGEN DOMINO PULSA TELKOMSEL | XL | AXIS 24 JAM
DIVAQQ | AGEN JUDI DOMINO DEPOSIT BEBAS 24 JAM
ReplyDeleteThis post is really nice and informative. The explanation given is really comprehensive and informative.I want to inform you about the salesforce business analyst training and Online Training Videos . thankyou . keep sharing..
You need to take part in a contest for one of the finest websites on the net. I will highly recommend this website!
ReplyDeleteBest Advanced Java Training In Bangalore Marathahalli
Advanced Java Courses In Bangalore Marathahalli
Advanced Java Training in Bangalore Marathahalli
Advanced Java Training Center In Bangalore
Advanced Java Institute In Marathahalli
Which is the last quota to go through the UEFA เว็บไซต์ พนันบอล Champions League As a result of the draw in this game, various situations Still have to cheer"The Blues" successfully defended the Carabao Cup after beating Aston Villa 2-1 in the final game. Last Sunday night Considered to win this title for three
ReplyDeletevery nice blogs!!! i have to learning for lot of information for this sites...Sharing for wonderful information. Thanks for sharing this valuable information to our vision. You have posted a trust worthy blog keep sharing
ReplyDeleteDigital Marketing In Telugu
Digital Marketing In Hyderabad
internet marketing
Digital marketing
Digital Marketing Strategy
Looking great work dear, I really appreciated to you on this quality work. Nice post!! these tips may help me for future.
ReplyDeleteNEET Exam Pattern
Spesial Promo Khusus Member Setia Di Situs CrownQQ
ReplyDeleteYuk Buruan Daftar Dan Mainkan 9 Game Berkualitas Hanya Di Situs CrownQQ
Agen BandarQ Terbesar Dan Terpercaya Di indonesia
Rasakan Sensasi serunya bermain di CrownQQ, Agen BandarQ Yang 100% Gampang Menang
Games Yang di Hadirkan CrownQQ :
* Poker Online
* BandarQ
* Domino99
* Bandar Sakong
* Sakong
* Bandar66
* AduQ
* Sakong
* Perang Baccarat (New Game)
Promo Yang Hadir Di CrownQQ Saat ini Adalah :
=> Bonus Refferal 20%
=> Bonus Turn Over 0,5%
=> Minimal Depo 20.000
=> Minimal WD 20.000
=> 100% Member Asli
=> Pelayanan DP & WD 24 jam
=> Livechat Kami 24 Jam Online
=> Bisa Dimainkan Di Hp Android
=> Di Layani Dengan 5 Bank Terbaik
<< Contact_us >>
WHATSAPP : +855882357563
LINE : CS CROWNQQ
TELEGRAM : +855882357563
Link Resmi CrownQQ:
RATUAJAIB. COM
RATUAJAIB.NET
RATUAJAIB.INFO
DEPOSIT VIA PULSA TELKOMSEL | XL 24 JAM NONSTOP
CROWNQQ | AGEN BANDARQ | ADUQ ONLINE | DOMINOQQ TERBAIK | DOMINO99 ONLINE TERBESAR
many of you often thought how to make money while having a great time. The site จีคลับ quite specifically provides an answer to these questions. Bakar Roulette Slots and more. Just have a try. 100% winnings can be easily withdrawn to your account
ReplyDeleteThis comment has been removed by the author.
ReplyDeletelinen cushion covers
pillow covers geometric
pillow covers solid
ok đó anh
ReplyDeletecửa lưới dạng xếp
cửa lưới chống muỗi
lưới chống chuột
cửa lưới chống muỗi hà nội
togel online
ReplyDeletebandar togel terpercaya
agen togel
judi togel
ดูหนังออนไลน์ movie
ReplyDeleteหนังโป๊ไทย
Bạn đã có bài viết khá hay
ReplyDeletehttps://bonngamchan.vn/may-massage-chan-hang-nhat-co-tot-nhu-loi-don/
https://bonngamchan.vn/
https://bonngamchan.vn/danh-muc/bon-ngam-chan/
https://bonngamchan.vn/may-ngam-chan/
Really Nice Post & Thanks for sharing.
ReplyDeleteOflox Is The Best Website Design Company In Dehradun
Tuyệt quá nah
ReplyDeletelều xông hơi
lều xông hơi tại nhà
lều xông hơi giá rẻ
lều xông hơi sau sinh
for entering the market through various บาคาร่าออนไลน์ channels in the country. Such as football analysis websites
ReplyDeleteGreat Information you have shared, Check it once selenium online training
ReplyDeleteTôi thích những gì bạn chia sẻ
ReplyDeletehttps://ngoctuyenpc.com/man-hinh-may-tinh-24-inch
https://ngoctuyenpc.com/mua-ban-may-tinh-cu-ha-noi
https://ngoctuyenpc.com/mua-ban-may-tinh-laptop-linh-kien-may-tinh-cu-gia-cao-tai-ha-noi
https://ngoctuyenpc.com/cay-may-tinh-cu
This are extremly blogs for everyone.
ReplyDeleteเว็บบาคาร่าขั้นต่ำ เว็บบาคาร่าขั้นต่ำ เว็บบาคาร่าขั้นต่ำ
I like to show my idea about this blog for you.
ReplyDeleteเว็บบาคาร่าขั้นต่ำ เว็บบาคาร่าขั้นต่ำ เว็บบาคาร่าขั้นต่ำ
I love this amazing blogs.
ReplyDeleteเว็บบาคาร่าขั้นต่ำ เว็บบาคาร่าขั้นต่ำ เว็บบาคาร่าขั้นต่ำ เว็บบาคาร่าขั้นต่ำ
I would like to show you about my blog.
ReplyDeleteทีเด็ดสปอร์ตพูลVIP ทีเด็ดสปอร์ตพูลVIP
ทีเด็ดสปอร์ตพูลVIP
Hello everyone, Are you into trading or just wish to give it a try, please becareful on the platform you choose to invest on and the manager you choose to manage your account because that’s where failure starts from be wise. After reading so much comment i had to give trading tips a try, I have to come to the conclusion that binary options pays massively but the masses has refused to show us the right way to earn That’s why I have to give trading tips the accolades because they have been so helpful to traders . For a free masterclass strategy kindly contact (paytondyian699@gmail.com) for a free masterclass strategy. He'll give you a free tutors on how you can earn and recover your losses in trading for free..
ReplyDeleteHello everyone, Are you into trading or just wish to give it a try, please becareful on the platform you choose to invest on and the manager you choose to manage your account because that’s where failure starts from be wise. After reading so much comment i had to give trading tips a try, I have to come to the conclusion that binary options pays massively but the masses has refused to show us the right way to earn That’s why I have to give trading tips the accolades because they have been so helpful to traders . For a free masterclass strategy kindly contact (paytondyian699@gmail.com) for a free masterclass strategy. He'll give you a free tutors on how you can earn and recover your losses in trading for free..
ReplyDelete
ReplyDeletefunny jokes
Thank you for the post. Its really resourceful.
ReplyDeleteReference: Stock Screener
Finology
nice post.thanks for sharing
ReplyDeletePhDassistance in india:
The HIGS software solution is a research and development company that offers a wide range of guidelines for doctoral students. We help PhD researchers achieve their goals by closing the gap between problems in the research vision and the practical implementation of technologies.
Why are we the best doctorates in India?
HIGS has years of experience in the industry and is one of the leading lecturers in India. All of our employees are experienced editors and research experts with many years of expertise.
What do we do?
University registration
We will help you register for a PhD at top universities such as IIT, JNTU, Anna University, VTU, Sathyabama University, Amity University, Hindustan University, NIT and more. Our research team will guide you to the selection of the specified domain and Completion of the topic. They also help you to identify the base paper in your domain.
Problem identification
Technical Readers Help you read concepts and help you identify the solutions to identified research problems.
Research paper writing
Technical editors will help you prepare the documentation for magazine, conference and accompanying documents and other reports.
Journal Paper Publications
Our experts will help you to publish your research in international journals such as IEEE, Springer, Elsevier, SCI journals and conferences.
Plagiarism check
100% original and plagiarism FREE work on writing checks Turnitin
Thesis & Synopsis Writing
We help you to do your PhD thesis. We deliver the best result.
Guide ship help
We help you to get a guide-ship in top universities in INDIA.
Deadline
The HIGS team knows the value of punctual transmission, and for this purpose we always deliver your order before the deadline.
So you can sit back and relax!
Visit our website here http://higssoftware.com/
Which course of study is very difficult?
ReplyDelete918kiss
สล็อต
Pussy888
Online Baccarat A gambling game that every gambler should try playing once in their life
ReplyDeleteOnline casino baccarat. By the way of play is similar to playing Pok 9 In which the dealer will deal 2-3 cards to each player to count the total points If anyone has a higher score Will be considered to win this game In which baccarat games are games that every gambling website must have for members to play Because it is a gambling game that gamblers play the highest number 1, so today we are going to write the advantages of playing baccarat online on various gambling websites.
Players have a lot of chances of winning the game.
Baccarat is a game where you have a lot of chances of winning the dealer. Usually, your chances of winning are either 0.5 or 50%, which is considered a lot when compared to other online gambling games such as Fantan games that only have a 0.25 or 25% win. Therefore, many people who want to win a simple game Therefore choose to play baccarat online instead
Playing baccarat online does not win, refunds
Play baccarat online, even if you do not win the dealer. You still have the opportunity to receive your money for placing a bet in full. Only you are always with the dealer. Considered a game that has little chance of losing money.
Baccarat has an easy way to play.
Baccarat online game Gambling-style gambling games that have easy to understand methods of playing. Maybe even easier than some card games Just you have to try to read how to play seriously once. You will definitely be able to play it. In which you may find articles to read more Or read in the rules and regulations that the website has on the website
Online baccarat games have a shortcut formula for you to use.
Playing baccarat online If you feel you can't play Or if your fortune is bad, you still have other ways to help you win the gambling game That is the use of short formulas for playing baccarat when you place bets.
Online game Baccarat has many promotions.
Playing baccarat online has promotions that are desirable to attract players. Giving the welcome bonus Credit back And commission when we invite friends to play with When you sign up on the website, you will give 100 - 300 baht free credit. In the website, there are also many types of games such as baccarat, roulette, bounce and slots. In addition, the website does not have a minimum deposit limit. money
The staff on the bara web site take good care of customers.
Within the online baccarat website, there are always staff available to serve you. Regardless of what questions you have, you can ask. Or if lazy to ask There are also frequently asked questions and answers for you to read on the web. Such websites will serve you like you are God. Regardless of whether you deposit money into the hundreds website Or deposit money into the millions of websites via the web. Baccarat is happy to serve you. The staff here regard every customer service to be of a good standard.
Online baccarat game is open for 24 hours.
Baccarat game is open for all players to play 24 hours, regardless of whether it feels free. When you feel hot Or when you feel like playing something fun You can come to play baccarat on this website.
And all of these are the advantages of online baccarat games. In addition to the advantages mentioned in this article There are other advantages that you will have to experience yourself.
บาคาร่า
Such a very useful article. Very interesting to read this article.I would like to thank you for the efforts you had made for writing this awesome article.
ReplyDeleteDevOps Training in Chennai | DevOps Training in anna nagar | DevOps Training in omr | DevOps Training in porur | DevOps Training in tambaram | DevOps Training in velachery
I am a antique 'Article' collector and I sometimes read some new articles if I find them interesting. uplay365 คาสิโนออนไลน์
ReplyDeletethank you for the article given to us. very useful and an inspiration for our site DEWA JUDI QQ
ReplyDeleteDewajudi88 DEWAQQ DEWAJUDI We are waiting for your article update on another occasion we will visit again.
เล่นเกมบาคาร่า sa มีดีกว่าที่คุณคิด
ReplyDeleteเมื่อเอ่ยถึงเกมบาคาร่า บาคาร่าออนไลน์ในปัจจุบัน นับว่าเป็นเกมที่ได้รับความนิยมอันดับที่หนึ่งของเว็บไซต์เกมคาสิโนออนไลน์ในสมัยปัจจุบันนี้เลยก็ว่าได้ ด้วยแบบอย่างเกมคาสิโนออนไลน์ที่ล้ำสมัยขึ้น เข้าถึงได้ง่ายมากยิ่งขึ้น รวมทั้งที่สำคัญสามารถทำเงินได้สูงมากขึ้น จากการเล่นเกมบาคาร่า โดยเหตุนั้นแม้คุณเป็นคนอีกคนหนึ่งที่พอใจ หรือพึงพอใจที่จะเข้ามาสืบเสาะหาโชคจากการเล่นเกมบาคาร่าออนไลน์ sa บาคาร่า เป็นเกมบาคาร่าอีกหนึ่งต้นแบบที่พวกเราต้องการจะเสนอแนะให้ท่านได้ทดลองเข้าไปเล่น รวมทั้งทำความรู้จัก เพราะว่า sa game นี้ เป็นค่ายเกมบาคาร่าออนไลน์ที่ใหญ่ที่สุด แล้วก็มีจุดเด่นที่น่าดึงดูด ที่เหมาะสมจะให้เหล่านักเล่นเกมบาคาร่าได้เข้าไปสร้างรายได้ด้วย ราทดลองไปดูกันว่าเกม sa จะเป็ยเกมที่น่าดึงดูดเช่นไร
ความน่าดึงดูดใจของเกม sa บาคาร่า
เกม sa บาคาร่า นับว่าเป็นหนึ่งในเกมคาสิโนออนไลน์ยอดนิยม รวมทั้งได้รับการตอบกลับอย่างดีเยี่ยมจากเหล่าผู้เล่นเกมคาสิโนออนไลน์ ซึ่งแม้คุณยังไม่เคยเล่นเกมคาสิโนออนไลน์ลักษณะนี้ พวกเราจะมาเอ๋ยถึงความน่าดึงดูดใจของ บาคาร่าsa ให้ท่านได้มองกัน
• Sa เป็นค่ายเกมบาคาร่าออนไลน์ที่คุณสามารถเชื่อถือได้ว่าไม่มีคดโกง ด้วยค่ายเกมบาคาร่าsa เป็นค่ายเกมที่อยู่คู่กับชาวไทยมาอย่างช้านาน มีบุคคลที่เข้าไปเล่นเกม sa มาอย่างช้านานด้วยเหตุนี้ตัดความรู้สึกกลุ้มใจหัวข้อการถูกหลอกเมื่อเล่นเกม sa ไปได้เลย
• บริการเกม sa บาคาร่า ได้เก็บเกมบาคาร่าหลายประเภทไว้ให้ท่านได้ทดลองเล่น ไม่ว่าจะเป็น บาคาร่าออนไลน์ บาคาร่าสด หรือบาคาร่าใดๆก็ตามเว็บไซต์คาสิโนของพวกเราจัดเต็มทุกเกมบาคาร่าเพื่อสมาชิกทุกท่าน
• สามารถเข้ามาเล่นเกม บาคาร่า sa ได้ตลอด 24 ชั่วโมง เพราพนี่เป็นเกมคาสิโนออนไลน์ที่ ที่ลุกรสามารถเข้ามาสร้างรายได้ได้ตลอดเมื่อคุณปรารถนา หรือสามารถเข้ามาศึกษาเล่าเรียนเคล็ดลับเพิ่มอีกเพื่อเล่นเกมบาคาร่ากับเว็บไซต์คาสิโนของพวกเราก็ได้
• บาคาร่า sa เป็นเกมคาสิโนออนไลน์ที่เล่นง่าย ได้เงินเร็วด้วยเกมบาคาร่า sa เป็นเกมคาสิโนออนไลน์ที่มีข้อตกลงการเล่นไม่ยาก แม้กระทั่งคุณเป็นนักเล่นเกมคนใหม่ ก็สามารถเข้ามาเล่นเกมบาคาร่ากับเว็บไซต์ของพวกเราได้อย่างไม่ต้องวิตกกังวล
โดยเหตุนั้นแม้คุณพึงพอใจที่จะเข้ามาเล่นเกมคาสิโนออนไลน์ สามารถเข้ามาถามข้อมูลอื่นๆ เกี่ยวกับการลงทะเบียนเป็นสมาชิกเว็บไซต์เกมเพื่อเล่นเกม sa บาคาร่ากับเว็บไซต์คาสิโนออนไลน์ของพวกเราได้เลยพวกเรามีคณะทำงานที่รอให้การช่วยเหลือคุณตลอด 24 ชั่วโมง จ่ายจริง โอนเร็ว เลือก sa king789
บาคาร่า
เกมบาคาร่าออนไลน์ไลน์ไหน ที่ใช้ไพ่เป็นอุปกรณ์สำคัญ
ReplyDeleteปัจจุบันนี้เกมบาคาร่าออนไลน์ เป็นที่แพร่หลาย และเป็นที่นิยมในหมู่คนที่ชื่นชอบการพนัน หรือการเสี่ยงโชคเป็นอย่างมาก ส่วนหนึ่งนั้นก็เพราะว่าการเล่นเกมบาคาร่าสามารถเข้าถึงได้ง่ายมากขึ้น สร้างรายได้ให้กับผู้เล่นได้จริงโดยที่ผู้เล่นเอง ก็ไม่ต้องออกไปทำงานหนักมากขึ้นกว่าเดิม แถมยังมีเวลาอยู่กับครอบครัวได้มากขึ้นกว่าเดิมด้วย ดังนั้นวันนี้หากคุณสนใจ หรือต้องการที่จะเข้ามาเล่นเกมบาคาร่า ไม่ว่าจะเป็นเกม บาคาร่าออนไลน์ สล็อตออนไลน์ หรือเกมบาคาร่าที่น่าสนใจไหนๆ ก็ต้องศึกษาและหากข้อมูลในการเล่นเกมให้ดี เพื่อประโยชน์ในการเล่นเกมของตัวคุณเอง
โดยวันนี้เราจะพาคุณไปรู้จักกับเกมบาคาร่า ที่ต้องใช้ ไพ่ เป็นอุปกรณ์สำคัญในการเล่นเกม ชนิดที่เรียกว่า ขาดไพ่ไม่ได้เลย อยากรู้ว่าจะมีเกมไหนที่น่าสนใจบ้างนั้นตามเราไปดูกันได้เลย
เกมบาคาร่าออนไลน์ที่ขนาด ไพ่ ไม่ได้
สำหรับการเล่นเกมบาคาร่าออนไลน์ แม้จะเป็นเกมที่ได้รับความนิยมขนาดไหนก็จาม ก็ยังมีข้อจำกัดในหลายๆเรื่องตัวอย่างเกมบาคาร่าต่างๆต่อไปนี้ ที่หากขาดอุปกรณ์สำคัญอย่างไพ่ ก็ไม่สามารถที่จะเล่นเกมนรูปแบบปัจจุบันได้เลย โดยตัวเอย่างเกมที่ต้องเล่นด้วยไพ่ คือ
• เกมบาคาร่าออนไลน์
มาที่เกมบาคาร่าออนไลน์แรกกันเลย กับเกม บาคาร่า ซึ่งเป็นหนึ่งเกมบาคาร่าออนไลน์ที่กำลังได้รับความนิยม และเป็นที่พูดถึงอย่างมากในปัจจุบัน ด้วยรูปแบบเกมที่มีความทันสมัย และมีหลากหลายรูปแบบให้ผู้ที่ชื่นชอบเกมพนันได้เข้าไปเล่น ที่สำคัญสามารถเลือกวางเงินเดิมพันได้ตามต้องการด้วย สะดวก สนุกกว่านี้ไม่มีอีกแล้ว
• เกมไพ่ป๊อกเด้ง
ต่อกันที่เกมไพ่ป๊อกเด้ง ที่ถ้าหากไม่มีไพ่ก็ไม่สามารถเล่นเกมนี้ได้อย่างแน่นอน เกมไพ่ป๊อกคงเป็นอีกหนึ่งเกมบาคาร่าที่อยู่คู่กับคนไทยมาอย่างยาวนาน ด้วยความสนุก และรูปแบบการเล่นที่เป็นเอกลักษณ์ ที่ผู้เล่นจะได้ทั้งความสนุก ความตื่นเต้น แบบที่หาจากเกมบาคาร่าไหนไม่ได้เลยทีเดียว
• เกมไพ่อื่นๆ
นอกจากเกมบาคาร่าออนไลน์ทั้งสองที่เราได้แนะนำไปแล้ว นอกจากนี้ก็ยังมีเกมบาคาร่าอื่นๆที่คุณไม่ควรพลาด และเป็นเกมบาคาร่าที่สร่างรายได้ให้กับผู้เล่นได้เป็นอย่างดีทีเดียว
ซึ่งนอกเหนือจากเกมไพ่ออนไลน์นี้แล้ว ก็ยังมีเกมรูปแบบอื่นๆที่น่าสนใจอีกมากมายที่กำลังรอให้คุณได้ลองเข้าไปเล่น และทำความรู้จักกับเกมบาคาร่าเหล่านี้อยู่ เรียกได้ว่า หากคุณไม่อยากพลาดความสนุก ความตื่นเต้น ตื่นตาตื่นใจ ก้อย่าพลาดที่จะเข้าไปเล่นเกมบาคาร่าออนไลน์กับเว็บของเรา
และเพื่อเป็นการเพิ่มความสนุกที่มากกว่านั้น คุณต้องรู้จักวิธีการเล่นเกมบาคาร่าที่คุณสนใจ และรู้จักศึกษาเทคนิคอื่นๆที่จะช่วยให้การเล่นเกทบาคาร่าของคุณ มีโอกาสในการทำเงินได้ง่ายมากขึ้นด้วย
บาคาร่า
August 2021 was my first time ever going abroad. Although I have seen many people from abroad in Hollywood (or Bollywood) movies, the impression of meeting with various kinds of people around the world cara menghilangkan jerawat made me so nervous. At first I thought that Americans are always blonde, white, and very tall. But, I knew that it wasn't true and some people had told me so. However, as I landed my feet on the US land, I couldn't resist to not asking questions in my head about the people around me. Why are some Americans very white, have a beautiful blonde hair, and their eyes are so blue as clear as water. I found out that it was rather intimidating for me. rental mobil jogja I am a south east Asian born with black hair, dark-brown eyes, brown skin, and a not-so-tall body. I wonder why God created us differently. Then I saw some people from other countries who are really black, I mean they have a very dark skin. In Indonesia, we sometimes identify skin color as white and black (it has nothing to do with racism), but what we mean by white is a very bright brown and what we mean by black is a very dark brown. It was just I had not seen someone like that yet. In addition, there are many other questions I asked. Why do they have such a thick accent, why do they love speaking so loud, or just why are they so tall.
ReplyDeleteI think stereotype sometimes help a lot in encouraging racism. For example, blonde usually is stereotyped as bad in mesothelioma vs lung cancer mathematics while Asians are usually very good in calculus and science. It is not always true for everyone, but it usually does. I have a friend who asked me, "Why are you so good in math? Is it because you are Asian?" I am sure he was just kidding, but he made me think. I have a part-time job as a tutor in a residential house and every night three to five students come in for help. Sometimes, they do need a lot of help in math, but sometimes their math isn't that bad. Some of them, as a matter of fact, do a wonderful job in other subjects but math. I was amazed by how good they are doing in biology, or graphic designs, or whatever they like. It made me realize that there are always good and bad in every person.
It took me some time to get used to people around me. In my sophomore year, I joined an International menghilangkan jerawat dan bekasnya Organization named Students for Global Connection. It is a group of International students (including Americans) that provides a place for International students to make friends and organize events together. I met wonderful students from different countries across the world and we had stories to tell. Yes, we have many differences and we always work on them. However, isn't it nice to taste a piece of other countries in the world from people who actually from that country? Last semester we had an event called the Worldwide Showcase. It is a cultural show performed by different groups of students from different countries. We provided a place for International Students to show their cultures and for American public to see other cultures. It was a pretty successful show, and we were proud of ourselves. Finally, I understood that the differences are to be respected Jasa SEO Judi
many of you often thought how to make money while having a great time. vscr888
ReplyDeleteSkor langsung sepakbola dari semua liga memiliki update cepat dan akurat untuk menit, skor, babak pertama dan hasil sepak bola penuh waktu, pencetak gol dan asisten, kartu, substitusi, statistik pertandingan dan live streaming hanya bersama kami livescore.
ReplyDeleteLayanan skor sepakbola langsung pada livescore888 menawarkan skor langsung sepak bola dan hasil sepak bola dari lebih dari 1000 liga sepak bola, piala dan turnamen (skor langsung Liga Premier, skor KPL dan Liga Champions), juga menyediakan tabel liga, pencetak gol, sorotan video, kuning dan kartu merah, peringatan gol dan informasi skor langsung sepak bola lainnya secara langsung. Dapatkan pemberitahuan dengan suara, ikuti pilihan skor Anda sendiri, beri tahu diri Anda tentang hasil sepak bola akhir serta skor langsung sepakbola. Layanan SofaScore sepakbola ini real time, Anda tidak perlu menyegarkannya. Di Livescore, Anda dapat menemukan skor Kenya Premier League, hasil EPL, skor Bundesliga, MLS, liga sepak bola Meksiko, dan mis. Sepak bola Australia atau PSL Afrika Selatan. Selain sepak bola, Anda dapat mengikuti lebih dari 30 olahraga di Livescore. Daftar lengkap olahraga dan jumlah kompetisi (hasil hari ini / semua kompetisi) di setiap olahraga dapat ditemukan di bagian Livescore.
ReplyDeleteออมเงินจากการเล่นเกมคาสิโน ทางเลือกใหม่ การเล่นเกมส์การเดิมพันpussy888
ReplyDeleteเข้าร่วมเล่นเกมส์การเดิมพันกับเว็บไซต์pussy888ของเรา ออมเงินจากการเล่นเกมส์การเดิมพัน ทำเงินจากการเล่นเกมส์การเดิมพันpussy888 ทางเลือกใหม่สำหรับคนที่มีความต้องการอยากจะทำเงินจากการเล่นเกมส์การเดิมพัน ทางเลือกใหม่สำหรับคนที่อยากจะสร้างรายได้เสริมจากการเล่นเกมส์การเดิมพันpussy888 ขอแนะนำให้กับเพื่อนๆทุกคนได้เข้าร่วมเล่นเกมส์การเดิมพันกับเว็บไซต์ของเรา ร่วมสนุกกับเกมการเดิมพัน และออมเงินจากการเล่นเกมส์การเดิมพันpussy888ได้ง่ายๆ เพียงแค่เปลี่ยนแนวคิด เปลี่ยนวิธีการเล่นเกมส์การเดิมพัน และเราจะเจอกับอีกหนึ่งช่องทาง เจอกับอีก 1 ประโยชน์ของการเล่นเกมpussy888
ออมเงินจากการเล่นเกมส์การเดิมพัน pussy888
เราสามารถออมเงินจากการเล่นเกมส์การเดิมพันpussy888ได้จริง เราสามารถออมเงิน และเราสามารถทำเงินจากการเล่นเกมส์การเดิมพันกับเว็บไซต์pussy888ของเราได้ เพราะฉะนั้น ใครที่อยากจะออมเงินจากการเล่นเกมส์การเดิมพันpussy888 ใครที่อยากจะทำเงินจากการเล่นเกมส์การเดิมพันคาสิโนpussy888 เป็นเว็บpussy888ที่เราอยากแนะนำให้กับเพื่อนๆ ได้เข้ามาร่วมเล่นเกมส์การเดิมพัน เล่นเกมส์การเดิมพันกับเว็บไซต์pussy888ของเราได้ง่ายๆ
ร่วมสนุกกับเกมการเดิมพัน และออมเงินจากการเล่นเกมส์การเดิมพันpussy888 ซึ่งก่อนอื่นเลย เราจะต้องเปลี่ยนนิสัยสำหรับการเล่นเกมส์การเดิมพันpussy888 ถ้าหากเราได้เงินจากการเล่นเกมส์การเดิมพันมาแล้ว เราจะต้องแบ่งเงินจากตรงนี้มาเป็นเงินออมบ้าง ออมเงินจากการเล่นเกมส์การเดิมพันนั้นสามารถทำได้จริง ถ้าหากเราสามารถเอาเงินจากการเล่นเกมส์การเดิมพันpussy888ได้ เราก็จะมีเงินไว้ใช้ในยามที่เราลำบาก เราจะเห็นประโยชน์ของการเล่นเกมส์การเดิมพันpussy888ได้เลยทันที
เปลี่ยนนิสัยสำหรับการเล่นเกมส์pussy888
เงินที่เพื่อนๆเข้ามาร่วมเล่นเกมส์การเดิมพันกับเว็บไซต์ของเราpussy888 ถ้าหากเพื่อนๆสามารถชนะเกมส์การเดิมพัน และสามารถทำเงินจากการเล่นเกมส์การเดิมพันpussy888ได้ เราอยากจะแนะนำให้กับเพื่อนๆออมเงิน ออมเงินกับเว็บของเรา ออมเงินจากการเล่นเกมส์การเดิมพันpussy888 ลองหักห้ามใจตัวเองสำหรับการใช้เงิน เงินที่เราได้มาคิดซะว่าเราได้มาจากการทำงาน มองเห็นถึงความสำคัญของเงินที่เราได้มา เราก็จะรู้สึกถึงคุณค่าของเงินมากยิ่งขึ้น
เพราะฉะนั้นถ้าหากอยากจะทำเงินจากการเล่นเกมส์การเดิมพัน เพราะฉะนั้นถ้าหากอยากจะเล่นเกมส์การเดิมพันpussy888 เข้าร่วมเล่นเกมส์การเดิมพันกับเว็บไซต์ของเราได้เลยตอนนี้pussy888 พร้อมบริการให้กับลูกค้าทุกคนได้เข้ามาร่วมเล่นเกมส์การเดิมพันกับสายของเรา
pussy888
Điều bạn viết tôi thực sự rất thích
ReplyDeletehttps://nhathuoctot.net/nhung-dieu-chua-biet-ve-giao-co-lam-9-la/
https://nhathuoctot.net/giao-co-lam-5-la-kho-hut-chan-khong-500gr/
https://nhathuoctot.net/giao-co-lam-hoa-binh/
https://nhathuoctot.net/cong-ty-ban-hat-methi-tot-tai-ha-noi/
thanks for sharing wonderful poster like this.very great blog.We offer the most budget-friendly quotes on all your digital requirements. We are available to our clients when they lookout for any help or to clear queries.
ReplyDeleteBest SEO Services in Chennai | digital marketing agencies in chennai | Best seo company in chennai | digital marketing consultants in chennai | Website designers in chennai
Hey Loved the post! Great article and congrats on Reaching the To 50! I will be back to visit often
ReplyDeletehttp://powerbitrainings.in/powerbi-training-institute-in-hyderabad/
Hey Loved the post! Great article and congrats on Reaching the To 50! I will be back to visit often
ReplyDeleteCara mudah dalam meriah keuntungan di dalam situs judi slot online terlengkap sangatlah mudah, cukup kunjungi dan mainkan beberapa permainan yang memberikan kemudahan kepada setiap member member yang mendaftar di dalam situs judi slot online terbaik dan terpercaya, dapatkan juga beberapa cara mudah dalam bermain di situs judi slot online dengan tips dan trik yang akan di berikan oleh situs resmi slot online sekarang.
ReplyDeleteForex Signals, MT4 and MT5 Indicators, Strategies, Expert Advisors, Forex News, Technical Analysis and Trade Updates in the FOREX IN WORLD
ReplyDeleteForex Signals Forex Strategies Forex Indicators Forex News Forex World
great post keep updating with us.River Group of Salon and spa, T.Nagar, provide a wide range of spa treatments, like body massage, scrub, wrap and beauty parlour services. We ensure unique care and quality service.
ReplyDeletemassage in T.Nagar|body massage T.Nagar|massage spa in T.Nagar|body massage center in T.Nagar|massage centre in chennai|body massage in chennai|massage spa in chennai|body massage centre in chennai|full body massage in T.Nagar
ReplyDeletepussy888
Very Helpful Article. Super bull It might help you. Super bull Thanks For Sharing
ReplyDeleteSuper bull Thank you very much.
Very Helpful Article. Super bull It might help you. Super bull Thanks For Sharing
ReplyDeleteSuper bull Thank you very much.
เล่นบอลออนไลน์ แทงบอลออนไลน์ พนันบอลไม่มีอย่างน้อย บริการะดับ VIP
ReplyDeleteเพราะเหตุไรจำเป็นต้องเลือกใช้บริการพนันกีฬาออนไลน์ตรงนี้ เพราะว่าเว็บพวกเราที่เปิดให้บริการมายาวนานกว่า 10 ปี มั่นคงรวมทั้งไม่เป็นอันตราย เป็นเว็บตรงไม่ผ่านเอเยนต์ บริการฝากและก็ถอนเร็วด้านใน 5-10 นาทีเพียงแค่นั้น แล้วก็ยังเป็นเว็บไซต์ที่ให้โบนัสสำหรับอีกทั้งสมาชิกใหม่และก็เก่ามากที่สุด นอกจากนั้นพวกเรายังเป็นผู้ช่วยเหลือหลักของสมาคมบอลนิวคาสเซิล ยูไนเต็ด และก็ชมรมท็อตแนม ฮ็อตสเปอร์ส สองสมาพันธ์บอลมีชื่อจากอังกฤษอีกด้วยก็เลยแน่ใจว่าพนันกีฬา พนันบอลสด กับพวกเราทุกหมวดหมู่นั้นจะได้รับความชอบธรรมแล้วก็ค่าแรงงานที่ดีไม่ต้องมากังวลว่าจะถูกโกงอย่างไม่ต้องสงสัยจ้ะ สมัคร ufabet
ReplyDeleteVery Helpful Articles. ufa.bet It might help you. ufa.bet Thanks For Sharing
ufa.bet Thank you very much.
Shield Security Solutions Offers Security Guard License Training across the province of Ontario. Get Started Today!
ReplyDeleteSecurity Guard License | Security License | Ontario Security license | Security License Ontario | Ontario Security Guard License | Security Guard License Ontario
Thankyou For infrormative informtion, keep it up and write more informative blog and if face any kind of issue regarding to QuickBooks Support Number dont go anywhere just call at +1-855-533-6333
ReplyDelete
ReplyDeleteI also lost about $75,000 to an IQ option broker and 2 fake binary option website as well but I am sharing my experience here so as to enlighten and educate everyone that is losing money or has lost money to a scam including binary options, dating scams,Recover all your lost money to Bitcoin and other Crypto currency, mortgage/realestate scams and fake ICOs.However , I have been able to recover all the money I lost to the scammers with the help of a recovery professional and I am pleased to inform you that there is hope for everyone that has lost money to scam. Contact this via mail (lisakimberly@gmail.com ) or via whatsapp (+18133243782) she will help you recover your funds.
excusme, is jaro-winkler as Fuzzy Search String? and is fuzzy search string same with fuzzy string match? thankyou
ReplyDeleteI just loved your article on the beginners guide to starting a blog.If somebody take this blog article seriously
ReplyDeletein their life, he/she can earn his living by doing blogging.Thank you for this article.
tibco sportfire online training
Informative post, Thank you. If you want to teach your kids with apps and online activities you have to check out this. The Learning Apps
ReplyDeleteBonus yang diberikan Pokervit :
ReplyDelete* Bonus rollingan 0.5%,setiap Jum'at di bagikannya
* Bonus Refferal 10%,seumur hidup
* Bonus Deposit Member Baru 20%
* Bonus Jackpot, yang dapat anda dapatkan dengan mudah
* Minimal Depo 10.000
* Minimal WD 50.000
AGEN IDN POKER99
DEPOSIT POKER99
Bonus yang diberikan Pokervit :
ReplyDelete* Bonus rollingan 0.5%,setiap Jum'at di bagikannya
* Bonus Refferal 10%,seumur hidup
* Bonus Deposit Member Baru 20%
* Bonus Jackpot, yang dapat anda dapatkan dengan mudah
* Minimal Depo 10.000
* Minimal WD 50.000
Download APK SuperBull 2.1.0
Daftar Poker 99 SuperBull
ไข่สั่นไร้สาย
ReplyDeleteThank you for sharing, I am very happy to know your blog. Here are some blogs I would like to send you. Please don't delete the link, hi
ReplyDeletemo da cong giao
game nổ hũ đổi thưởng
game bắn cá đổi thưởng
làm cavet xe uy tín
Arabic Sweets
ReplyDeleteI simply couldn't resist praising the way you play with words. This is a perfect example of a well-written blog post.
ReplyDeletevé máy bay tết 2021 jetstar
Bảng giá vé máy bay Vietjet Air
vé máy bay bmt đà nẵng vietjet
vé máy bay vietjet hà nội cam ranh
vé máy bay giá rẻ hải phòng phú quốc
vé máy bay đi quy nhơn
bitsourceit
ReplyDeleteDevops training in chennai
ReplyDeleteNice Blog !
ReplyDeleteQuickBooks is an accounting software that helps you record the flow of your company's finance. In case you want immediate help to solve QuickBooks issues, call us on QuickBooks Customer Support Number and get in touch with our experts.
Wonderful Blog. Keep Posting.
ReplyDeleteCorporate Excel Training in Mumbai
Advanced Excel Corporate Training in Bangalore
Corproate Excel Training Delhi, Gurgaon, Noida
Corporate Excel Training in Hyderabad
Corporate Excel Training in Pune
Garlic Bulb Cutting Machine
ReplyDeleteGarlic Peeling Machine
Garlic Peeling Machine
Removing Machine
Silage Machine
Peanut Peeling Machine
http://pengeluaransgp88.com menyediakan info perihal pengeluaran SGP terbaru
ReplyDeleteJangan ragu klik keluaran sgp dapatkan bonus yang berlimpah http://keluaransgp88.com/
ReplyDeletekeluaran honkong adalah situs yang menyajikan prediksi paling di tunggu http://keluaranhongkong88.com/
ReplyDeleteThank you for your blog , it was usefull and informative
ReplyDelete"AchieversIT is the best Training institute for react js training.
react training in bangalore
"
You’re so interesting! I don’t believe I’ve truly read something like this before. So great to find someone with genuine thoughts on this issue. Really.. many thanks for starting this up. This website is something that’s needed on the internet, someone with some originality!
ReplyDeleteCBSE Schools In Junagadh
CBSE Schools In Kheda
CBSE Schools In Kutch
CBSE Schools In Mehsana
CBSE Schools In Morbi
CBSE Schools In Narmada
CBSE Schools In Navsari
CBSE Schools In Panchmahal Godhra
CBSE Schools In Patan
CBSE Schools In Porbandar
ReplyDeleteSitus Terpercaya Seindonesia
Bandar Poker
AduQ
BandarQ
Perang Dadu
Bandar66
Poker
BD Q
Sakong
Capsasusun
Domino 99
Perang Baccarat
-PERMAINAN BANDARQQ TERPERCAYA-
ReplyDeleteDAFTAR SEKARANG DAN DAPATKAN BONUS BESAR
TURNOVER - 0,BONUS 5%
BONUS REFERRAL - 20%
DAN BONUS BESAR LAINNYA
KLIK DISINI-PERMAINAN BANDARQQ TERPERCAYA-
DAFTAR SEKARANG DAN DAPATKAN BONUS BESAR
TURNOVER - 0,BONUS 5%
BONUS REFERRAL - 20%
DAN BONUS BESAR LAINNYA
KLIK DISINI
bandar togel online kingdomgrup juga mempunyai banyak bonus bonus dan game game jackpot lainnya http://128.199.187.54/
ReplyDeleteThanks for sharing your info. I truly appreciate your efforts
ReplyDeleteand I will be waiting for your next pos thanks once
again.https://insider-betting.com
https://highstreetbetting.org
https://sportsbettingtopsystem.com
no deposit bonus forex 2021 - takipçi satın al - takipçi satın al - takipçi satın al - takipcialdim.com/tiktok-takipci-satin-al/ - instagram beğeni satın al - instagram beğeni satın al - google haritalara yer ekleme - btcturk - tiktok izlenme satın al - sms onay - youtube izlenme satın al - google haritalara yer ekleme - no deposit bonus forex 2021 - tiktok jeton hilesi - tiktok beğeni satın al - binance - takipçi satın al - uc satın al - finanspedia.com - sms onay - sms onay - tiktok takipçi satın al - tiktok beğeni satın al - twitter takipçi satın al - trend topic satın al - youtube abone satın al - instagram beğeni satın al - tiktok beğeni satın al - twitter takipçi satın al - trend topic satın al - youtube abone satın al - instagram beğeni satın al - tiktok takipçi satın al - tiktok beğeni satın al - twitter takipçi satın al - trend topic satın al - youtube abone satın al - instagram beğeni satın al - perde modelleri - instagram takipçi satın al - instagram takipçi satın al - cami avizesi - marsbahis
ReplyDeleteStudiopress SEO Service
ReplyDeleteRegenbox SEO Service
Aiatlanta SEO Service
Sub4sub SEO Service
Morsbags SEO Service
Strata SEO Service
Ugazdinky SEO Service
Windsurf SEO Service
Cope4u SEO Service
Bunkersnack SEO Service
Ucraya SEO Service
Madinamerica SEO Service
Themecatcher SEO Service
Heromachine SEO Service
Mds-foundation SEO Service
Thegardenstrust SEO Service
Espressobin SEO Service
Axlethemes SEO Service
Forums.geomywp SEO Service
inmoov SEO Service
progettokublai SEO Service
muzoplus SEO Service
knkusa SEO Service
SEO Service
SEO Service
pulse-station SEO Service
isalp SEO Service
nexusconsultancy SEO Service
rockwheelers SEO Service
SEO Service
physicaltherapist SEO Service
mtm-international SEO Service
Situs Agen Slot Online Pragmatic Juragan69, Ayo Gabung dan bermain Bersama Agen Judi Slot Online Indonesia Terpercaya Juragan69, Dapatkan Berbagai macam Games judi Slot Online Uang Asli Juragan69, dan Jangan lupa Bermain Bersama Juragan69 untuk mendapatkan Bonus terbaik dari kami agar anda merasa puas bermain bersama Juragan69!
ReplyDeletejudi slot online indonesia terpercaya 2021
daftar situs slot online terpopuler dan terbaik
Bandar judi slot online terbaik 2021
daftar agen slot online resmi 2021
website situs judi slot online terbesar
agen pragmatic online bandar togel 98toto mempunyai jackpot yang besar sampai ratusan ribu dolar
ReplyDeletekingdom grup Agen Togel Online paling amanah dan terpercaya
ReplyDeleteSlot Online KINGDOM jackpot hadiahnya
ReplyDeleteDAFTAR TEMPAT MELIHAT LIVE SCORE : GOALOO LIVE SCORE
ReplyDeleteDengan bermain berjudi casino online mau senantiasa mencari untuk dimainkan diiringi seluruh Kemudahan Memasang Taruhan Casino Up-to-date yg boleh member memiliki sesekali bermain pada situs terpercaya.
ReplyDeleteSesungguhnya game update tersebut mirip saja diikuti game casino pada international nyata. Penjudi pula dapat memperoleh beragam kemudahan yg atas semenjak game casino dengan up-to-date ini. https://abc-online-casino.net Berikut itu sejumlah kemudahan dari berjudi casino dengan update tersebut.
Ayo Mari Gabung dan Main Slot Online Disini
ReplyDeleteMainkan Slot Online Pulsa Dengan Rate 100% Tanpa Potongan Disini
Situs Livescore Goaloo Adalah Yang Tercepat Mengupdate Hasil Pertandingan Bola
ReplyDeleteTemukan Hasil Livescore di Nowgoal Goaloo Disini
PG Soft 123 adalah Website PG Soft terbaik dan terpercaya dan telah hadir di indonesia dan telah dimainkan oleh banyak player di indonesia
ReplyDeletehttps://www.a6iaf.net/
Thanks for sharing such useful information with us. I hope you will share some more info about your blog. Please keep sharing. We will also provide QuickBooks Customer Service Phone Number for instant help.
ReplyDeletedo this and feeling good
ReplyDeleteslot gacor online indonesia
PG Soft 88 | Website PG Soft Games terbaik dan telah dimainkan oleh para player slot di Indonesia
ReplyDeletePG Soft 88
under jacket Pragmatic 88
ReplyDelete