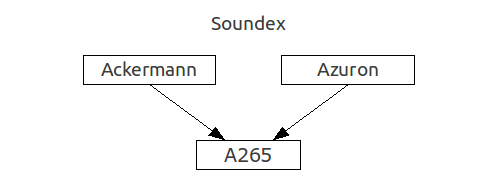
Часто довольно трудно найти в базе нетипичную фамилию, например:
— Леха, поищи в нашей базе Адольфа Швардсенеггера,В этом случае использование фонетических алгоритмов (особенно в сочетании с алгоритмами нечеткого сопоставления) может значительно упростить задачу.
— Шворцинегира? Нет такого!
Такие алгоритмы очень удобно использовать при поиске в базах по спискам людей, в программах проверки орфографии. Зачастую они используются совместно с алгоритмами нечеткого поиска (которые, несомненно, заслуживают отдельной статьи), предоставляя пользователям удобный поиск по именам и фамилиям в различных базах данных, списках сотрудников и так далее.
В этой статье я рассмотрю наиболее известные алгоритмы, такие как Soundex, Daitch-Mokotoff Soundex, NYSIIS, Metaphone, Double Metaphone, русский Metaphone, Caverphone.
Soundex
Одним из первых был алгоритм Soundex, изобретенный еще в 10-x годах прошлого века Робертом Расселом. Этот алгоритм (а точнее, его американская версия) сопоставляет словам численный индекс вида A126. Принцип его работы основан на разбиении согласных букв на группы с порядковыми номерами, из которых затем и составляется результирующее значение. Позднее также был предложен ряд улучшений.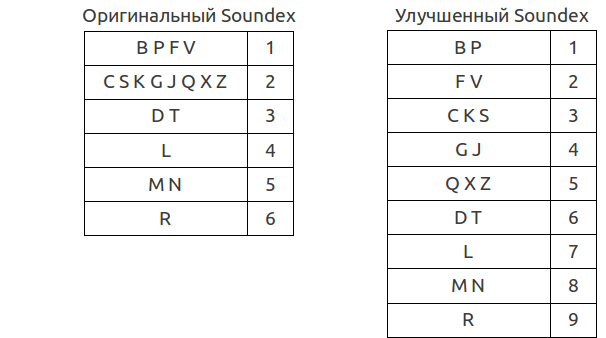
Первая буква сохраняется, последующие буквы сопоставляются цифрам по таблице. Символы, не представленные в таблице (а это все гласные и некоторые согласные), игнорируются. Смежные символы, или символы, разделенные буквами H или W, входящие в одну и ту же группу, записываются как один. Результат обрезается до 4 символов. Недостающие позиции заполняются нулями. Несложно заметить, что после всех этих процедур остается всего лишь 7 тысяч различных вариаций такого кода, что влечет за собой множество совершенно ничем не похожих друг на друга слов, имеющих одинаковый Soundex-код. Таким образом, результат в большинстве случаев включает в себя большое количество "ложноположительных" значений.
В улучшенной версии, как можно заметить, буквы разбиты на большее количество групп. Помимо этого, никакого особого внимания буквам H и W не уделяется, они просто игнорируются. Кроме того, никаких операций с длиной результата не производится - код не имеет фиксированной длины и не обрезается.
Примеры
Оригинальный Soundex:D341 → Дедловский, Дедловских, Дидилев, Дителев, Дудалев, Дудолев, Дутлов, Дыдалев, Дятлов, Дятлович.
N251 → Нагимов, Нагмбетов, Назимов, Насимов, Нассонов, Нежнов, Незнаев, Несмеев, Нижневский, Никонов, Никонович, Нисенблат, Нисенбаум, Ниссенбаум, Ногинов, Ножнов.
Улучшенный Soundex:
N8030802 → Насимов, Нассонов, Никонов.
N80308108 → Нисенбаум, Ниссенбаум.
N8040802 → Нагимов, Нагонов, Неганов, Ногинов.
N804810602 → Нагмбетов.
N8050802 → Назимов, Нежнов, Ножнов.
В среднем, на одно значение кода Soundex приходится 21 фамилия. В случае же улучшенной версии Soundex, к одному и тому же коду преобразуются всего 2-3 фамилии.
NYSIIS
Разработанный в 1970 году как часть системы "New York State Identification and Intelligence System", этот алгоритм дает несколько лучшие результаты относительно оригинального Soundex, используя более сложные правила преобразования исходного слова в результирующий код. Этот алгоритм разработан для работы именно с американскими фамилиями.Алгоритм вычисления кода NYSIIS
- Преобразовать начало слова по следующим правилам:
MAC → MCC
KN → N
K → C
PH, PF → FF
SCH → SSS - Преобразовать конец слова по следующим правилам:
EE → Y
IE → Y
DT, RT, RD, NT, ND → D - Затем все буквы, кроме первой, преобразуются по следующим правилам:
EV → AF
A, E, I, O, U → A
Q → G
Z → S
M → N
KN → N
K → C
SCH → SSS
PH → FF
После гласных: удалить H, преобразовать W → A - Удалить S на конце
- Преобразуем AY на конце → Y
- Удалить A на конце
- Обрезать до 6 символов (необязательный шаг).
Примеры
CASPARAVAS → Каспаравичус, Касперович, Каспирович.CATNACAV → Катников, Цитников, Цотников.
LANSANC → Ленченко, Леонченко, Линченко, Лунченко, Лямзенко.
PRADSC → Приходский, Проходский, Прудский, Прудских, Прудской.
STADNACAV → Стадников.
NYSIIS преобразует к одному и тому же коду немногим более двух фамилий.
Daitch-Mokotoff Soundex
Этот алгоритм в 1985 году разработали два генеалога - Гарри Мокотофф и Рэнди Дэйч, стремясь достичь лучших, относительно оригинального Soundex, результатов при работе со восточно-европейскими (в том числе русскими) фамилиями.Этот алгоритм имеет мало общего с оригинальным Soundex, разве что результатом всё так же остается последовательность цифр, однако теперь первая буква также кодируется.
Он имеет значительно более сложные правила конверсии - теперь в формировании результирующего кода участвуют не только одиночные символы, но и последовательности из нескольких символов. Кроме того, результат вида 023689 обеспечивает около 600 тысяч различных вариаций кода, что вкупе с усложненными правилами уменьшает количество "лишних", т.е. "ложноположительных" слов в результирующем множестве.
Преобразования осуществляются по следующей таблице (порядок преобразований соответствует порядку буквосочетаний в таблице):
| Исходные буквосочетания | В начале | За гласной | Остальное |
| AI, AJ, AY, EI, EY, EJ, OI, OJ, OY, UI, UJ, UY | 0 | 1 | |
| AU | 0 | 7 | |
| IA, IE, IO, IU | 1 | ||
| EU | 1 | 1 | |
| A, UE, E, I, O, U, Y | 0 | ||
| J | 1 | 1 | 1 |
| SCHTSCH, SCHTSH, SCHTCH, SHTCH, SHCH, SHTSH, STCH, STSCH, STRZ, STRS, STSH, SZCZ, SZCS | 2 | 4 | 4 |
| SHT, SCHT, SCHD, ST, SZT, SHD, SZD, SD | 2 | 43 | 43 |
| CSZ, CZS, CS, CZ, DRZ, DRS, DSH, DS, DZH, DZS, DZ, TRZ, TRS, TRCH, TSH, TTSZ, TTZ, TZS, TSZ, SZ, TTCH, TCH, TTSCH, ZSCH, ZHSH, SCH, SH, TTS, TC, TS, TZ, ZH, ZS | 4 | 4 | 4 |
| SC | 2 | 4 | 4 |
| DT, D, TH, T | 3 | 3 | 3 |
| CHS, KS, X | 5 | 54 | 54 |
| S, Z | 4 | 4 | 4 |
| CH, CK, C, G, KH, K, Q | 5 | 5 | 5 |
| MN, NM | 66 | 66 | |
| M, N | 6 | 6 | 6 |
| FB, B, PH, PF, F, P, V, W | 7 | 7 | 7 |
| H | 5 | 5 | |
| L | 8 | 8 | 8 |
| R | 9 | 9 | 9 |
CH → TCH
CK → TSK
C → TZ
J → DZH
Примеры
095747 → Архипцев, Архипцов, Архипычев, Арцыбасов, Арцыбашев, Арчибасов095757 → Архипков, Архипцев, Архипцов, Архипычев
584360 → Галстян, Галустян, Гильштейн, Глистин, Глуздань, Голштейн, Гольдштеин, Гольдштейн, Калустьян, Хлистун, Хлыстун, Хлюстин.
К одному и тому же коду этот алгоритм преобразует в среднем 5 фамилий.
Впоследствии Александр Бейдер и Стивен Морзе разработали Beider-Morse Name Matching Algorithm, нацеленный на уменьшение количества "ложноположительных" значений относительно Daitch-Mokotoff Soundex при работе с еврейскими (ашкенази) фамилиями.
Metaphone
Несколько лучшими характеристиками обладает алгоритм Metaphone (1990 год), отличающийся от предыдущих алгоритмов несколько иным подходом к процессу кодирования: он преобразует исходное слово с учетом правил английского языка, используя заметно более сложные правила, и при этом теряется значительно меньше информации, так как буквы не разбиваются на группы. Итоговый код представляет собой набор символов из множества 0BFHJKLMNPRSTWXY, в начале слова также могут быть гласные из множества AEIOU.Алгоритм вычисления кода Metaphone
- Удаляем все повторяющиеся соседние буквы, за исключением буквы C.
- Начало слова преобразовать по следующим правилам:
KN → N
GN → N
PN → N
AE → E
WR → R - Удаляем на конце букву B, если она идет после M.
- Заменяем C по следующим правилам
На Х: CIA → XIA, SCH → SKH, CH → XH
На S: CI → SI, CE → SE, CY → SY
На K: C → K - Заменяем D по следующим правилам
На J: DGE → JGE, DGY → JGY, DGI → JGY
На T: D → T - Заменяем GH → H, если это буквосочетание стоит не в конце и не перед гласной.
- Заменяем GN → N и GNED → NED, если эти буквосочетания стоят в конце.
- Заменяем G по следующим правилам
На J: GI → JI, GE → JE, GY → JY
на K: G → K - Удаляем все H, идущие после гласных, но не перед гласными.
- Выполняем последующие преобразования по правилам:
CK → K
PH → F
Q → K
V → F
Z → S - Заменяем S на X:
SH → XH
SIO → XIO
SIA → XIA - Заменяем T по следующим правилам
На X: TIA → XIA, TIO → XIO
На 0: TH → 0
Удаляем: TCH → CH
- В начале слова преобразовать WH → W. Если после W нет гласной, то удалить W.
- Если X в начале слова, то преобразовать X → S, иначе X → KS
- Удалить все Y, которые не находятся перед гласными.
- Удалить все гласные, кроме начальной.
Примеры
AKXN → Агашин, Акаченок, Акишин, Аксионенко, Аксионов, Акчунаев, Акшанов, Акшенцев, Акшинский, Акшинцев, Акшонов.FSLX → Василишин, Васильчак, Васильченко, Васильчик, Васильчиков, Васильченко, Васильчук, Василющенко.
SRFM → Серафимов, Серафимский, Серафимчук, Церейфман.
Одно и то же значение кода Metaphone имеют в среднем 6 фамилий.
Double Metaphone
Double Metaphone (2000 год) несколько отличается от других фонетических алгоритмов, генерируя из исходного слова не один, а два кода (оба длиной до 4 символов) - один отражает основной вариант произношения слова, другой же - альтернативную версию. Он имеет большое количество различных правил, учитывающих, помимо всего прочего, различное происхождение слов, уделяя внимание восточно-европейским, итальянским, китайским словам и так далее. Правила преобразований достаточно многочисленны, я не буду их публиковать, а желающие смогут прочитать о них в статье журнала Dr Dobbs.Примеры
JXRF → Гишаров.KKRF → Гагаров, Кагаров, Качаровский, Качеровский, Качуривский, Качуров, Качуровский, Кичеров, Кокарев, Кокоуров, Кокоуров, Кочаров, Кочуров, Кукарев, Цакиров, Цокуров, Цугров.
KXRF → Гишаров, Гочаров, Качеров, Качеровский, Кашаревский, Кочаров, Кочерев, Кочеряев, Кочураев, Кошарев, Кошеров.
PNFS → Бановский, Бахновский, Биневский, Бинявский, Буйновский, Буяновский, Паневский, Пановский, Пановских, Пеньевский, Пиневский, Пиуновский, Пихновский.
Double Metaphone сопоставляет в среднем 8-9 фамилий одному и тому же коду.
Русский Metaphone
В 2002 году в 8-ом выпуске журнала "Программист" была опубликована статья Петра Каньковски, рассказывающая о его адаптации английской версии алгоритма Metaphone к суровым сибирским морозам, медведям и балалайкам. Этот алгоритм преобразует исходные слова в соответствии с правилами и нормами русского языка, учитывая фонетическое звучание безударных гласных и возможные "слияния" согласных при произношении. Он показывает очень хорошие результаты на практике, несмотря на то, что основывается на довольно простых правилах. Все буквы разбиты на группы по звучанию - гласные и согласные (vowels и consonants соответственно в английской терминологии), глухие и звонкие. Звонкие согласные преобразуются в соответствующие им парные глухие, объединяются "сливающиеся" при произношении последовательности букв, и проводятся некоторые другие манипуляции. Ниже я приведу немного доработанный вариант, который, в отличие от оригинала Петра Каньковски, привносит правила, связанные с фонетической эквивалентностью Ц и ТС или ДС, и не сжимает окончания - байты экономить - это не наша задача.Алгоритм вычисления кода русского Metaphone
- Для всех гласных букв проделать следующие операции.
ЙО, ИО, ЙЕ, ИЕ → И
О, Ы, Я → А
Е, Ё, Э → И
Ю → У - Для всех согласных букв, за которыми следует любая согласная, кроме Л, М, Н или Р, либо же для согласных на конце слова, провести оглушение:
Б → П
З → С
Д → Т
В → Ф
Г → К - Склеиваем ТС и ДС в Ц:
ТС → Ц
В случае Адольфа Швардсенеггера результатом работы алгоритма русского Metaphone будет:
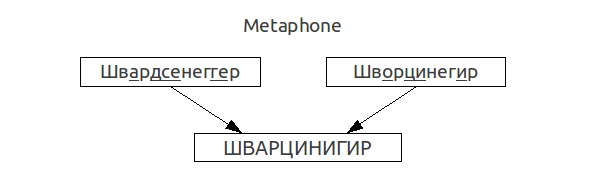
Таким образом, алгоритм в данном случае отражает реальное фонетическое сходство этих двух фамилий.
Примеры
ВИТАФСКИЙ → Витавский, Витовский.ВИТИНБИРК → Витенберг, Виттенберг.
НАСАНАФ → Насанов, Насонов, Нассонов, Носонов.
ПИРМАКАФ → Пермаков, Пермяков, Перьмяков.
Этот алгоритм преобразует к одному и тому же коду в среднем 1-2 фамилии.
Caverphone
Алгоритм Caverphone был разработан в 2002 году в рамках одного из новозеландских проектов для сопоставления данных в старых и новых электоральных списках, потому он наиболее ориентирован на местное произношение, хотя и для русских фамилий он дает вполне приемлемые результаты.Алгоритм вычисления кода Caverphone
- Преобразовать имя или фамилию в нижний регистр (алгоритм чувствителен к регистру).
- Удалить буквы e на конце.
- Преобразовать начало слова по следующей таблице (актуально для местных новозеландских имен и фамилий). При этом цифра 2 означает временную метку для согласной буквы, которая впоследствии будет удалена.
cough rough tough enough gn mb cou2f rou2f tou2f enou2f 2n m2 - Провести замены символов по следующей таблице:
cq ci ce cy tch c q x v dg tio tia d ph b sh z 2q si se sy 2ch k k k f 2g sio sia t fh p s2 s - Заменить все гласные в начале слова на A, в остальных случаях - на 3. Таким образом, цифра 3 служит временной меткой для гласной буквы, которая будет использоваться в последующих преобразованиях, а затем будет удалена. После, необходимо провести замены по следующим таблицам (условные обозначения: s+ - несколько идущих подряд символов, ^h - символ в начале строки, w$ - символ на конце строки):
j ^y3 ^y y 3gh3 gh g s+ t+ p+ k+ f+ m+ y Y3 A 3 3kh3 22 k S T P K F M n+ w3 wh3 w$ w ^h h r3 r$ r l3 l$ l N W3 Wh3 3 2 A 2 R3 3 2 L3 3 2 - Удалить все цифры 2. Если на конце слова осталась цифра 3, то заменить её на A. Затем удалить все цифры 3.
- Обрезать слово до 10 символов, либо же дополнить до 10 символов единицами.
Примеры
KPRLN11111 → Габрелян, Габриэлян, Габриэльян, Капарулин, Капралин, Капрелян.MSRFK11111 → Мейзерович, Мисарович, Мисюревич.
PLLF111111 → Балалаев, Балалиев, Балалуев, Билалиев, Билалов, Билялов, Болелов, Палилов, Полилов, Полуляхов.
Caverphone сопоставляет одному и тому же коду около 4-5 фамилий.
Итого
Большая часть этих алгоритмов реализована на множестве языков, в том числе на C, C++, Java, C# и PHP. Некоторые из них, например Soundex и Metaphone, интегрированы или реализованы в виде плагинов для многих популярных СУБД, а также используются в составе полноценных поисковых движков, например, Apache Lucene. Область их применения довольно специфична, ведь значительного повышения удобства для пользователей можно добиться лишь при поиске фамилий, но тем не менее грамотное их использование - это плюс для поисковых систем.Ссылки
- Код на Java к статье. Яндекс.Диск
- Реализации Soundex, Refined Soundex, Metaphone, Double Metaphone, Caverphone на Java.
Apache Commons Codec - Реализация NYSIIS на Java. Проект Egothor
- Реализация Daitch-Mokotoff Soundex на Java. http://joshualevy.tripod.com/genealogy/dmsoundex/dmsoundex.zip
- Описание Soundex. http://en.wikipedia.org/wiki/Soundex
- Описание Daitch-Mokotoff Soundex. http://www.jewishgen.org/infofiles/soundex.html
- Описание NYSIIS.
http://en.wikipedia.org/wiki/New_York_State_Identification_and_Intelligence_System - Описание Metaphone. http://en.wikipedia.org/wiki/Metaphone
- Описание Double Metaphone. http://www.drdobbs.com/article/184401251
- Описание русского Metaphone. http://forum.aeroion.ru/topic461.html
- Описание Caverphone. http://en.wikipedia.org/wiki/Caverphone
- Онлайн-демо Soundex. http://www.gedpage.com/soundex.html
- Онлайн-демо NYSIIS. http://www.dropby.com/NYSIIS.html
- Онлайн-демо Daitch-Mokotoff Soundex. http://stevemorse.org/census/soundex.html
- Онлайн-демо Metaphone. http://www.searchforancestors.com/utility/metaphone.php
English version: Phonetic algorithms
На Хабрахабре: Фонетические алгоритмы
I really enjoyed this post reallyBest game for Nintedno switch
ReplyDeleteamazing one. very informative and useful article, Keep doing a greats post. I wait more and more information from you
Thanks for providing such a nice information. this post is really helpful. It takes strengths to build for the future.. it was really nice that you decided to share this information. LIC Policy India
ReplyDeleteReally very happy to say, your post is very interesting to read. I never stop myself to say something about it. You’re doing a great job. Keep it up
ReplyDeleteBest Way To Get Cash For Junk Cars
I rarely share my story with people, not only because it put me at the lowest point ever but because it made me a person of ridicule among family and friends. I put all I had into Binary Options ($690,000) after hearing great testimonies about this new investment
ReplyDeletestrategy. I was made to believe my investment would triple, it started good and I got returns (not up to what I had invested). Gathered more and involved a couple family members, but I didn't know I was setting myself up for the kill, in less than no time all we had put ($820,000) was gone. It almost seem I had set them up, they came at me strong and hard. After searching and looking for how to make those scums pay back, I got introduced to maryshea03@gmail.com to WhatsApp her +15623847738.who helped recover about 80% of my lost funds within a month.
I wait more and more information from you uplay365 คาสิโนออนไลน์
ReplyDeleteslot online yang paling bnyak di cari judi online yg menguntungkan doyan303 nya hanya disini,.mari mulai bermain dengan kita di https://206.189.94.79
ReplyDeleteExcellent post! Your post is very useful and I felt quite interesting reading it. Expecting more post like this. Thanks for posting such a good post. laptop service in home. To service your laptop with offer prices, Please visit : Laptop service center in Navalur
ReplyDelete